持久化方式和文件存储知识学习整理
2016-08-27 » iOS开发基础iOS持久化方式 有哪些
1、NSUserDefaults
2、NSKeyedArchiver
3、沙盒Document
4、sqlite3
5、KeyChain
持久化分为两类:沙盒内和沙盒外。
出于安全考虑,iOS系统的沙盒机制规定每个应用都只能访问当前沙盒目录下面的文件(也有例外,比如在用户授权情况下访问通讯录,相册等),这个规则展示了iOS系统的封闭性。
一、沙盒目录结构和各个目录的路径获取方法
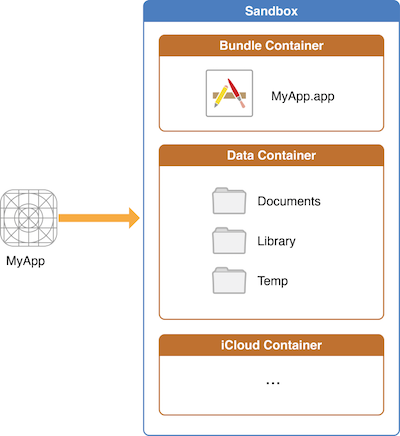
在应用开发中,如果要保存沙盒中某个文件路径,注意不要保存全路径,只能保存在沙盒中的相对路径,否则会导致路径访问错误。这是因为每次重新编译安装应用时,沙盒目录路径会改变。以下是对每个文件夹的作用进行说明:
AppName.app : 应用程序包目录,包含应用程序和所需资源。由于应用程序必须经过签名,所以您在运行时不能对这个目录中的内容进行修改,否则可能会使应用程序无法启动。
Documents:您应该将所有的应用程序数据文件写入到这个目录下。这个目录用于存储用户数据。该路径可通过配置实现iTunes共享文件。会被iTunes同步。
Documents/Inbox:用来存放由外部应用请求当前应用程序打开的文件,会被iTunes同步。
Library:下面有两个目录,该路径下的文件夹,除Caches以外,都会被iTunes备份。
Preferences:包含应用程序的偏好设置文件。您不应该直接创建偏好设置文件,而是应该使用NSUserDefaults类来取得和设置应用程序的偏好。结果在目录下面以plist的方式存储
Caches:用于存放应用程序专用的支持文件,保存应用程序再次启动过程中需要的信息。可创建子文件夹。可以用来放置您希望被备份但不希望被用户看到的数据。
tmp:用来存放应用再次启动时不需要的临时文件,该目录下的东西随时可能被系统清理掉,不会被iTunes同步。
沙盒主目录
// 获取沙盒主目录路径
NSString *homeDir = NSHomeDirectory();
Documents目录
// 获取Documents目录路径
NSString *docDir = [NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES) firstObject];
// 存放文件
NSString *path = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES).firstObject;
NSString *fileName = [path stringByAppendingPathComponent:@"myfile"];
NSString *content = @"测试数据";
NSData *contentData = [content dataUsingEncoding:NSUTF8StringEncoding];
BOOL result = [contentData writeToFile:fileName atomically:YES];
//文件存放在Documents目录
Library目录
// 获取Library的目录路径
NSString *libDir = [NSSearchPathForDirectoriesInDomains(NSLibraryDirectory, NSUserDomainMask, YES) lastObject];
// 获取Caches目录路径
NSString *cachesDir = [NSSearchPathForDirectoriesInDomains(NSCachesDirectory, NSUserDomainMask, YES) firstObject];
// 缓存文件存放和Documents目录存放文件一样
//Preferences 通过 NSUserDefault存数据
tmp目录
// 获取tmp目录路径
NSString *tmpDir = NSTemporaryDirectory();
// 缓存文件存放和Documents目录存放文件一样
AppBundle目录路径
// 获取AppBundle目录路径
NSLog(@"%@",[[NSBundle mainBundle] bundlePath]);
NSString *imagePath = [[NSBundle mainBundle] pathForResource:@"apple" ofType:@"png"];
UIImage *appleImage = [[UIImage alloc] initWithContentsOfFile:imagePath];
二、沙盒内的持久化方式
NSKeyedArchiver 归档
1、什么是归档
归档是一种很常用的文件存储方法,可以存储各种类型的对象(以文件的方式保存)。
官方提供了NSKeyedArchiver和NSKeyedUnarchiver两个类以供我们把对象序列化和反序列化,在存储之前使用NSKeyedArchiver进行序列化操作,并且写入本地文件,在使用之前使用NSKeyedUnarchiver进行反序列化的操作,以供提取使用
2、使用场景
如果是简单的基础数据类型,我们一般使用的是NSUserDefaults 或者 plist文件存储
对于一些量级比较大的,有规律可循的我们一般使用sqlite3数据库、coreData等
但是对于对象级别,轻量级的存储,我们一般可以使用归档来完成。
3、归档的使用方法
1、了解NSCoding 和 NSSecureCoding,NSCoding安全性不高,所以iOS6的时候,苹果引入了NSSecureCoding协议,加强安全性。
2、需要序列化的类需要实现 NSCoding 或者 NSSecureCoding 协议(推荐使用NSSecureCoding),并复写方法:
- (void)encodeWithCoder:(NSCoder *)coder
- (instancetype)initWithCoder:(NSCoder *)coder
3、NSKeyedArchiver 和 NSKeyedUnarchiver,NSKeyedArchiver将自定义的类转换成NSData实例,类里面每一个值对应一个Key;NSKeyedUnarchiver将NSData实例根据key值还原成自定义的类。
NSKeyedArchiver 归档操作现在不推荐使用下面两个操作(被苹果废弃)
+ (NSData *)archivedDataWithRootObject:(id)rootObject
+ (BOOL)archiveRootObject:(id)rootObject toFile:(NSString *)path
推荐使用
+ (nullable NSData *)archivedDataWithRootObject:(id)object requiringSecureCoding:(BOOL)requiresSecureCoding error:(NSError **)error
4、归档、解档
NSData * data = [NSKeyedArchiver archivedDataWithRootObject:me requiringSecureCoding:YES error:&error];
Person *newPerson = (Person *)[NSKeyedUnarchiver unarchivedObjectOfClass:Person.class fromData:data error:&error];
5、例子:
@interface Person : NSObject <NSSecureCoding>
@property (nonatomic, strong) NSString *name;
@end
-------------------------------------------
@implementation Person
- (void)encodeWithCoder:(NSCoder *)coder
{
[coder encodeObject:self.name forKey:@"name"];
}
- (instancetype)initWithCoder:(NSCoder *)coder
{
self = [super init];
if (self) {
self.name = [coder decodeObjectForKey:@"name"];
}
return self;
}
+ (BOOL)supportsSecureCoding {
return true;
}
@end
-------------------------------------------
Person *me = [[Person alloc]init];
me.name = @"小白";
NSString *homeDir = NSHomeDirectory();
NSError *error;
NSData * data = [NSKeyedArchiver archivedDataWithRootObject:me requiringSecureCoding:YES error:&error];
NSLog(@"%@",error);
Person *newPerson = (Person *)[NSKeyedUnarchiver unarchivedObjectOfClass:Person.class fromData:data error:&error];
NSLog(@"%@",error);
NSLog(@"%@",newPerson.name);
4、归档文件的存放
归档操作生成的data文件,可以通过文件存储的方式,存放到沙盒中
NSUserDefaults
1、存取
[NSUserDefaults standardUserDefaults]获取NSUserDefaults对象,以key-value方式进行持久化操作。
存
[[NSUserDefaults standardUserDefaults] setObject:array forKey:@"array"];
取
NSMutableArray *mutableArr = [NSMutableArray arrayWithArray:[defaults objectForKey:@"mutableArr"]];
2、应用场景
存放一些基础数据、如判断条件等,自动登录信息。
3、注意事项
1、可以存储的对象有NSString、NSArray、NSDictionary、NSData、NSNumber
2、我们还要注意NSUserDefaults存储的对象全是不可变的,就算你存的时候是可变的,最后都会被转成不可变的
比如 NSMutableArray 存储后取出时NSArray,是不可变的,需要重新构建 NSMutableArray
NSMutableArray *mutableArr = [NSMutableArray arrayWithArray:[defaults objectForKey:@"mutableArr"]];
3、对相同的key赋值等于一次覆盖,所以请保证key的唯一性
Plist存储、文件存储
1、plist
可以存储的对象有NSString、NSArray、NSDictionary、NSData、NSNumber
写入使用writeToFile,读取使用xxxWithContentsOfFile;需要指定文件路径。
写入:
NSMutableArray * array = [[NSMutableArray alloc]initWithObjects:@"小白", @"蜡笔小新", nil];
//获取Document目录地址,拼接上文件名称
NSString *path = [[NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES) firstObject] stringByAppendingPathComponent:@"data.plist"];
[array writeToFile:path atomically:YES];
读取:
NSMutableArray * new_array = [NSMutableArray arrayWithContentsOfFile:path];
NSLog(@"%@",new_array);
2、文件
这里要和plist区分一下,plist方式是字典/数组数据格式写入文件;而这里的文件方式不限数据格式。
数据库 sqlite3 (FMDB)
数据库无疑是大量数据最好的持久化方案,数据库目前有:sqlite、CoreData和Realm等。
1、SQLite
SQLite是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。它是一个零配置的数据库,这意味着与其他数据库一样,您不需要在系统中配置。
1、不需要一个单独的服务器进程或操作的系统(无服务器的)
2、SQLite 不需要配置,这意味着不需要安装或管理
3、一个完整的 SQLite 数据库是存储在一个单一的跨平台的磁盘文件
4、SQLite 是非常小的,是轻量级的,完全配置时小于 400KB,省略可选功能配置时小于250KB
5、SQLite 是自给自足的,这意味着不需要任何外部的依赖
6、SQLite 事务是完全兼容 ACID 的,允许从多个进程或线程安全访问
1.ACID事务
2.零配置 – 无需安装和管理配置
3.储存在单一磁盘文件中的一个完整的数据库
4.数据库文件可以在不同字节顺序的机器间自由的共享
5.支持数据库大小至2TB
6.足够小, 大致13万行C代码, 4.43M
7.比一些流行的数据库在大部分普通数据库操作要快
8.简单, 轻松的API
9.包含TCL绑定, 同时通过Wrapper支持其他语言的绑定
10.良好注释的源代码, 并且有着90%以上的测试覆盖率
11.独立: 没有额外依赖
12.源码完全的开源, 你可以用于任何用途, 包括出售它
13.支持多种开发语言,C, C++, PHP, Perl, Java, C#,Python, Ruby等
SQLite将数据划分为以下几种存储类型:
NULL : NULL 值
integer : 整型值
real : 浮点值
text : 文本字符串
blob : 二进制数据(比如文件)
没有 Boolean 没有用于存储日期和/或时间的类型,可用其他类型代替
实际上SQLite是无类型的,就算声明为integer类型,还是能存储字符串文本(主键除外)
2、FMDB使用
1、什么是FMDB
iOS中使用C语言函数对原生SQLite数据库进行增删改查操作,复杂麻烦,于是,就出现了一系列将SQLite API封装的库,如FMDB
FMDB是针对libsqlite3框架进行封装的三方,它以OC的方式封装了SQLite的C语言的API,使用步骤与SQLite相似
2、FMDB优缺点
FMDB的优点是:
(1) 使用时面向对象,避免了复杂的C语言代码
(2) 对比苹果自带的Core Data框架,更加轻量级和灵活
(3) 提供多线程安全处理数据库操作方法,保证多线程安全跟数据准确性
FMDB缺点:
(1) 因为是OC语言开发,只能在iOS平台上使用,所以实现跨平台操作时存在限制性
3、相关类
FMDatabase:一个FMDatabase对象代表一个单独的SQLite数据库,通过SQLite语句执行数据库的增删改查操作
FMResultSet:使用FMDatabase对象查询数据库后的结果集
FMDatabaseQueue:用于多线程操作数据库,它保证线程安全
3、sqlite锁
sqlite的锁的粒度比较粗,是数据库级别的,也就是说即使只是对某个页进行读写操作,sqlite也会封锁整个数据库。这种策略降低了读-写事务和写-写事务间的并发程度,但是大大简化了程序设计,减小了整个程序的大小。所以,sqlite的适用场景为:较少次写入数据,大量、多次读出数据。这也是sqlite作为一款嵌入式数据库的设计初衷。
sqlite读事务获取锁的过程:UNLOCKED-->SHARED->进行读取操作
sqlite写事务获取锁的过程:UNLOCKED->SHARED->RESERVED->创建回滚日志,在数据库内存页中写入数据,刷新日志文件到磁盘->PENDING->EXCLUSIVE->刷新内存页中的数据到磁盘。
SQLite使用锁逐步上升机制,为了写数据库,连接需要逐级地获得排它锁。
SQLite有5个不同的锁状态:
未加锁(UNLOCKED)
共享 (SHARED)
保留(RESERVED)
待定(PENDING)
排它(EXCLUSIVE)。
每个数据库连接在同一时刻只能处于其中一个状态。每 种状态(未加锁状态除外)都有一种锁与之对应。
最初的状态是未加锁状态,在此状态下,连接还没有存取数据库。当连接到了一个数据库,甚至已经用BEGIN开始了一个事务时,连接都还处于未加锁状态。
未加锁状态的下一个状态是共享状态。为了能够从数据库中读(不写)数据,连接必须首先进入共享状态,也就是说首先要获得一个共享锁。多个连接可以 同时获得并保持共享锁,也就是说多个连接可以同时从同一个数据库中读数据。但哪怕只有一个共享锁还没有释放,也不允许任何连接写数据库。
如果一个连接想要写数据库,它必须首先获得一个保留锁。一个数据库上同时只能有一个保留锁。保留锁可以与共享锁共存,保留锁是写数据库的第1阶段。保留锁即不阻止其它拥有共享锁的连接继续读数据库,也不阻止其它连接获得新的共享锁。
一旦一个连接获得了保留锁,它就可以开始处理数据库修改操作了,尽管这些修改只能在缓冲区中进行,而不是实际地写到磁盘。对读出内容所做的修改保存在内存缓冲区中。
当连接想要提交修改(或事务)时,需要将保留锁提升为排它锁。为了得到排它锁,还必须首先将保留锁提升为待定锁。获得待定锁之后,其它连接就不能再获得新的共享锁了,但已经拥有共享锁的连接仍然可以继续正常读数据库。此时,拥有等待锁的连接等待其它拥有共享锁的连接完成工作并释放其共享锁。
一旦所有其它共享锁都被释放,拥有待定锁的连接就可以将其锁提升至排它锁,此时就可以自由地对数据库进行修改了。所有以前对缓冲区所做的修改都会被写到数据库文件。
4、sqlite的死锁
举例:
两个连接 A 和 B 同时但完全独立地工作于同一个数据库。A执行第1条命令,B执行第2、3条,等等。
A连接 B连接
sqlite> BEGIN;
sqlite> BEGIN;
sqlite> INSERT INTO foo VALUES('x');
sqlite> SELECT * FROM foo;
sqlite> COMMIT;
SQL error: database is locked
sqlite> INSERT INTO foo VALUES ('x');
SQL error: database is locked
两个连接都在死锁中结束。B首先尝试写数据库,也就拥有了一个待定锁。A再试图写,但当其INSERT语句试图将共享锁提升为保留锁时失败。
为了讨论的方便,假设连接A和B都一直等待数据库可写。那么此时,其它的连接甚至都不能够再读数据库了,因为B拥有待定锁(它能阻止其它连接获得共享锁)。那么时此,不仅A和B不能工作,其它所有进程都不能再操作此数据库了。
解决死锁的办法:sqlite用锁超时的机制处理死锁
如果避免此情况呢?答案是采用正确的事务类型来完成工作。
事务的种类
SQLite有三种不同的事务,使用不同的锁状态。
事务可以开始于:DEFERRED、MMEDIATE 或 EXCLUSIVE。
事务类型在BEGIN命令中指定:
BEGIN [ DEFERRED | IMMEDIATE | EXCLUSIVE ] TRANSACTION;
一个DEFERRED事务不获取任何锁(直到它需要锁的时候),BEGIN语句本身也不会做什么事情——它开始于UNLOCK状态。默认情况下就是这样的,如果仅仅用BEGIN开始一个事务,那么事务就是DEFERRED的,同时它不会获取任何锁;当对数据库进行第一次读操作时,它会获取 SHARED锁;同样,当进行第一次写操作时,它会获取RESERVED锁。
IMMEDIATE事务会尝试获取RESERVED锁。如果成功,BEGIN IMMEDIATE保证没有别的连接可以写数据库。但是,别的连接可以对数据库进行读操作;但是,RESERVED锁会阻止其它连接的BEGIN IMMEDIATE或者BEGIN EXCLUSIVE命令,当其它连接执行上述命令时,会返回SQLITE_BUSY错误。这时你就可以对数据库进行修改操作了,但是你还不能提交,当你 COMMIT时,会返回SQLITE_BUSY错误,这意味着还有其它的读事务没有完成,得等它们执行完后才能提交事务。
EXCLUSIVE事务会试着获取对数据库的EXCLUSIVE锁。这与IMMEDIATE类似,但是一旦成功,EXCLUSIVE事务保证没有其它的连接,所以就可对数据库进行读写操作了。
上节那个例子的问题在于两个连接最终都想写数据库,但是它们都没有放弃各自原来的锁,最终,SHARED锁导致了问题的出现。如果两个连接都以 BEGIN IMMEDIATE开始事务,那么死锁就不会发生。在这种情况下,在同一时刻只能有一个连接进入BEGIN IMMEDIATE,其它的连接就得等待。BEGIN IMMEDIATE和BEGIN EXCLUSIVE通常被写事务使用。就像同步机制一样,它防止了死锁的产生。
基本的准则是:如果你正在使用的数据库没有其它的连接,用BEGIN就足够了。但是,如果你使用的数据库有其它的连接也会对数据库进行写操作,就得使用BEGIN IMMEDIATE或BEGIN EXCLUSIVE开始你的事务。
那么,如何启动,提交还有回滚事务呢?SQLite中分别是:BEGIN、COMMIT和ROLLBACK。
5、数据库知识
1、数据库分类
关系型数据库
MySQL等
非关系型数据库
MongoDB等
2、SQLite常用语句的使用
1、常用关键字
select、insert、update、delete、from、create、where、desc、order、by、group、table、alter、view、index等等
2、语句种类
DDL:数据定义语句 : create(创建)、alter(修改)、drop(删除)
create table if not exists 表名 (字段名1 字段类型1, 字段名2 字段类型2, …) ;
create table t_student (id integer, name text, age integer, score real) ;
ALTER TABLE table_name RENAME TO new_table_naler ;
DROP table if exists 表名 ;
DROP table t_student ;
--------------------------------------------------
DML:数据操作语句
包括insert、update、delete等操作
上面的3种操作分别用于添加、修改、删除表中的数据
insert into 表名 (字段1, 字段2, …) values (字段1的值, 字段2的值, …) ;
insert into t_student (name, age) values (‘mj’, 10) ;
update 表名 set 字段1 = 字段1的值, 字段2 = 字段2的值, … ;
update t_student set name = ‘jack’, age = 20 ;
delete from 表名 ;
delete from t_student ;
--------------------------------------------------
DQL:数据库查询语句
关键字select是DQL(也是所有SQL)用得最多的操作
--------------------------------------------------
like子句
百分号(%)代表零个、一个或多个数字或字符。下划线(_)代表一个单一的数字或字符。这些符号可以被组合使用。
SELECT FROM table_name
WHERE column LIKE 'XXXX%'
or
SELECT FROM table_name
WHERE column LIKE '%XXXX%'
or
SELECT FROM table_name
WHERE column LIKE 'XXXX_'
or
SELECT FROM table_name
WHERE column LIKE '_XXXX'
or
SELECT FROM table_name
WHERE column LIKE '_XXXX_'
--------------------------------------------------
Glob 子句 :和LIKE一样是通配符匹配, 与 LIKE 不同的是,GLOB 是大小写敏感的
星号(*)代表零个、一个或多个数字或字符。问号(?)代表一个单一的数字或字符。这些符号可以被组合使用。
--------------------------------------------------
LIMIT 子句用于限制由 SELECT 语句返回的数据数量。
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows] OFFSET [row num]
SQLite 引擎将返回从OFFSET下一行开始 [no of rows] 行。
--------------------------------------------------
ORDER BY 子句是用来基于一个或多个列按升序或降序顺序排列数据。
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
--------------------------------------------------
GROUP BY 子句用于与 SELECT 语句一起使用,来对相同的数据进行分组。
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
--------------------------------------------------
HAVING 子句允许指定条件来过滤将出现在最终结果中的分组结果。
WHERE 子句在所选列上设置条件,而 HAVING 子句则在由 GROUP BY 子句创建的分组上设置条件。
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
在一个查询中,HAVING 子句必须放在 GROUP BY 子句之后,必须放在 ORDER BY 子句之前。下面是包含 HAVING 子句的 SELECT 语句的语法:
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
--------------------------------------------------
DISTINCT 关键字与 SELECT 语句一起使用,来消除所有重复的记录,并只获取唯一一次记录。
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
3、SQLite的索引
索引(Index)是一种特殊的查找表,数据库搜索引擎用来加快数据检索。简单地说,索引是一个指向表中数据的指针。一个数据库中的索引与一本书后边的索引是非常相似的。
1、索引不应该使用在较小的表上。
2、索引不应该使用在有频繁的大批量的更新或插入操作的表上。
3、索引不应该使用在含有大量的 NULL 值的列上。
4、索引不应该使用在频繁操作的列上。
CREATE INDEX 命令
CREATE INDEX index_name ON table_name;
唯一索引:使用唯一索引不仅是为了性能,同时也为了数据的完整性。唯一索引不允许任何重复的值插入到表中。
CREATE INDEX index_name
on table_name (column_name);
组合索引:组合索引是基于一个表的两个或多个列上创建的索引。
CREATE INDEX index_name
on table_name (column1, column2);
隐式索引
隐式索引是在创建对象时,由数据库服务器自动创建的索引。索引自动创建为主键约束和唯一约束。
DROP INDEX 命令
一个索引可以使用 SQLite 的 DROP 命令删除。当删除索引时应特别注意,因为性能可能会下降或提高。
DROP INDEX index_name;
4、SQLite的约束
约束是在表的数据列上强制执行的规则。这些是用来限制可以插入到表中的数据类型。这确保了数据库中数据的准确性和可靠性。
NOT NULL 约束:确保某列不能有 NULL 值。
DEFAULT 约束:当某列没有指定值时,为该列提供默认值。
UNIQUE 约束:确保某列中的所有值是不同的。
PRIMARY Key 约束:唯一标识数据库表中的各行/记录。
CHECK 约束:CHECK 约束确保某列中的所有值满足一定条件。
CREATE TABLE COMPANY3(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL UNIQUE,
ADDRESS CHAR(50) DEFAULT 'home',
SALARY REAL CHECK(SALARY > 0)
);
5、SQLite事务
1、事务(Transaction)是一个对数据库执行工作单元。事务(Transaction)是以逻辑顺序完成的工作单位或序列,可以是由用户手动操作完成,也可以是由某种数据库程序自动完成。
2、事务(Transaction)是指一个或多个更改数据库的扩展。例如,如果您正在创建一个记录或者更新一个记录或者从表中删除一个记录,那么您正在该表上执行事务。重要的是要控制事务以确保数据的完整性和处理数据库错误。
3、事务(Transaction)具有以下四个标准属性,通常根据首字母缩写为 ACID:
原子性(Atomicity):确保工作单位内的所有操作都成功完成,否则,事务会在出现故障时终止,之前的操作也会回滚到以前的状态。
一致性(Consistency):确保数据库在成功提交的事务上正确地改变状态。
隔离性(Isolation):使事务操作相互独立和透明。
持久性(Durability):确保已提交事务的结果或效果在系统发生故障的情况下仍然存在。
4、事务控制
BEGIN TRANSACTION:开始事务处理 或者BEGIN。
//中间是自己需要完成的数据库操作
COMMIT:保存更改,或者可以使用 END TRANSACTION 命令。
ROLLBACK:回滚所做的更改。
sqlite> BEGIN;
sqlite> DELETE FROM COMPANY WHERE AGE = 25;
sqlite> ROLLBACK;
6、SQLite的提高查询速度方法
1、关键搜索词索引的建立
索引并不是越多越好
注意会增大数据库大小,可以显著提高select的速度,同时也可以提高update的速度
2、查询sql的优化
尽量查找id
减少全表扫描 如:
避免sql中 where子句后面使用表达式
避免where子句中使用 or连接,可以通过联合
in not in 也要慎用
7、提高写入速度
1、事务开启可以提高查询效率,因为避免了频繁的函数调用,插入后一次性提交。
2、关闭写入同步
在SQLite中,数据库配置的参数都由编译指示(pragma)来实现的,而其中synchronous选项有三种可选状态,分别是full、normal、off。full写入速度最慢,但保证数据是安全的,不受断电、系统崩溃等影响,而off可以加速数据库的一些操作,但如果系统崩溃或断电,则数据库可能会损毁。如果有定期备份的机制,而且少量数据丢失可接受
sqlite3_exec(db,"PRAGMA synchronous = OFF; ",0,0,0);
3、使用执行准备
就算开起了事务,SQLite仍然要对循环中每一句SQL语句进行“词法分析”和“语法分析”,这对于同时插入大量数据的操作来说,简直就是浪费时间。使用执行准备,即先将SQL语句编译好,然后再一步一步(或一行一行)地执行。
四、沙盒外的持久化方式
KeyChain
沙盒内的方式在应用被删除后数据都会丢失,如果想要不丢失则需要使用KeyChain。 KeyChain本质是一个sqlite数据库,其保存的所有数据都是加密过的。 KeyChain分为私有和公有,公有则需要指定group,一个group中的应用可以共享此KeyChain。 使用KeyChain过程中要理解下面几个问题:
1:自己使用的KeyChain和系统自带的KeyChain数据是隔离的,内部应该是不同数据库文件;
2:KeyChain数据可备份到iCloud中;
3:不需要联网,也不用登陆iCloud账号;一个设备一个sqlite数据库,但是不同应用组不共享数据;
4:要在另一台设备上使用当前设备存储的KeyChain信息,需要当前设备进行数据备份,
再在另一设备上复原数据;比较常用的是iCloud备份方式;
5:系统自带的KeyChain中账号密码分类数据可在系统设置->账号与密码里面看到,
你退出iCloud账号还是存在,只是iCloud会帮你备份如果你设置了的话;这个和照片是一样的道理。