数据结构
2016-05-03 » iOS开发基础数组 (Array)
1、数组元素在内存上连续存放,可以通过下标查找元素;插入、删除需要移动大量元素,比较适用于元素很少变化的情况
2、静态数组(NSArray),内容不可改变,从栈中分配空间,不能存放基础类型, 自由度小
3、静态数组的变量本身就是数组第一个元素的地址
字典 (NSDictionary)
NSDictionary(字典)是使用 hash表来实现key和value之间的映射和存储的, hash函数设计的好坏影响着数据的查找访问效率。数据在hash表中分布的越均匀,其访问效率越高。而在Objective-C中,通常都是利用NSString 来作为键值,其内部使用的hash函数也是通过使用 NSString对象作为键值来保证数据的各个节点在hash表中均匀分布。
队列 (Queue)
队列是一种特殊的线性表,特殊之处在于它只允许在表的 前端(head) 进行删除操作,而在表的后端(tail) 进行插入操作,队列是一种操作受限制的线性表。进行插入操作的端称为队尾 ,进行删除操作的端称为队头 。
队列特点是先进先出,后进后出。
比如 NSOpeartionQueue 和 GCD 的 各种队列 ,其特点都是先进先出(First In First out), 在多线程执行执行多个任务时候, 放进同一队列的任务是顺次从队列里取出任务并执行的。
队列在我们生活中也很常见,比如排队购票 去银行办理业务排队办理业务,都是队首的办理完业务后,离开柜台 下一个人接着办理业务
最简单的队列实现就是一个数组,实现一个进队列 和 一个出队列的方法(头部移除)
链表(Linked List)
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。
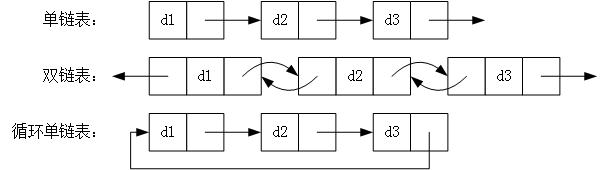
总结来说,相比较普通的线性结构,链表结构的优势是单个节点创建非常方便,普通的线性内存通常在创建的时候就需要设定数据的大小;节点的删除非常方便,不需要像线性结构那样移动剩下的数据;节点的访问方便,可以通过循环或者递归的方法访问到任意数据,但是平均的访问效率低于顺序表。
数组和链表区别:
数组:数组元素在内存上连续存放,可以通过下标查找元素;插入、删除需要移动大量元素,比较适用于元素很少变化的情况
链表:链表中的元素在内存中不是顺序存储的,查找慢,插入、删除只需要对元素指针重新赋值,效率高
单链表
单向链表是最简单的链表形式。我们将链表中最基本的数据称为节点(node),每一个节点包含了数据块和指向下一个节点的指针。
带头节点
不带头节点
单链表的模拟实现
OC:
.h文件
///////链表存放对象
@interface Person : NSObject
@property (nonatomic, strong) NSString *name;
@end
///////链表节点
@interface LinkedNode : NSObject
@property (nonatomic, strong) Person *data;
@property (nonatomic, strong) LinkedNode *next;
@end
///////链表
@interface LinkedList : NSObject
@property (nonatomic, strong) LinkedNode *head;
@property (nonatomic, strong) LinkedNode *tail;
@end
.m文件
///////链表节点
@implementation LinkedNode
- (instancetype)initWithData:(Person *) data
{
self = [super init];
if (self) {
self.data = data;
self.next = nil;
}
return self;
}
@end
///////链表
@implementation LinkedList
///////初始化带头部链表
- (instancetype)init
{
self = [super init];
if (self) {
self.head = [[LinkedNode alloc]init];
self.head.next = nil;
self.tail= self.head;
}
return self;
}
///////添加链表,头部添加
- (void)appendToHeadWithData:(Person *)data {
LinkedNode *node = [[LinkedNode alloc]initWithData:data];
node.next = self.head.next;
self.head.next = node;
}
///////添加链表,尾部添加
- (void)appendToTailWithData:(Person *)data {
LinkedNode *node = [[LinkedNode alloc]initWithData:data];
node.next = self.tail.next;
self.tail.next = node;
self.tail = node;
}
///////删除指定位置节点
- (Person *)deleteWithHead:(LinkedNode *)head andNum:(int)num {
if (head.next == nil || num < 1) { return nil; }
int i = 0;
LinkedNode *node = head;
LinkedNode *p;
Person *data;
while (i++ < num - 1) { node = node.next; }
p = node.next;
if (p == NULL ) { return nil; }
data = p.data;
node.next = node.next.next;
return data;
}
///////判断链表是否为空
- (BOOL)isEmpty { return self.head.next == NULL; }
- (void)print {
LinkedNode *head = self.head;
while (head != nil) {
if (head.data != NULL) {
NSLog(@"%@",head.data.name);
}
head = head.next;
}
}
@end
Swift: 枚举写链表
枚举可以实现了一个只能增加不能删减的链表
indirect enum LinkedList<Element: Comparable> {
case Empty
case Head
case Node(Element, LinkedList<Element>)
static func start() -> LinkedList {
return LinkedList.Head
}
func append(data: Element) -> LinkedList {
return LinkedList.Node(data, self)
}
func description() {
var list = self
while case let LinkedList.Node(element, next) = list {
print(element)
list = next
}
}
}
如果要实现完整的逻辑还是得用class
class LinkedList<T>: NSObject {
class LinkedNode<T>: NSObject {
var data: T?
var next: LinkedNode<T>?
override init() {
super.init()
}
init(withData data: T) {
super.init()
self.data = data
}
}
var head: LinkedNode<T>
var tail: LinkedNode<T>
override init() {
let node = LinkedNode<T>()
node.next = nil
head = node
tail = head
super.init()
}
func appendToHead(withData data: T) {
let node = LinkedNode<T>(withData: data)
node.next = self.head.next
self.head.next = node
}
func appendToTail(withData data: T) {
let node = LinkedNode<T>(withData: data)
node.next = self.tail.next
self.tail.next = node
self.tail = node
}
func description() {
var node: LinkedNode<T>? = self.head
while node != nil {
print(node?.data)
node = node?.next
}
}
}
双链表
循环链表
散列表(Hash)
1、数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系
2、能够具备数组的快速查询的优点又能融合链表方便快捷的增加删除元素的优势,简单的说就是散列,即将输入的数据通过hash函数得到一个key值,输入的数据存储到数组中下标为key值的数组单元中去,我们发现,不相同的数据通过hash函数得到相同的key值。这时候,就产生了hash冲突。解决hash冲突的方式有两种。一种是挂链式,也叫拉链法。挂链式的思想在产生冲突的hash地址指向一个链表,将具有相同的key值的数据存放到链表中。另一种是建立一个公共溢出区。将所有产生冲突的数据都存放到公共溢出区,也可以使问题解决。
哈希表的查找效率
影响哈希表的查找效率主要问题是冲突问题,如果冲突较多,查找效率就会低。 冲突原因主要是以下三个
哈希函数是否均匀; 哈希冲突处理的方法; 哈希表的负载因子 。
哈希表的负载因子 = 填入表中的元素个数 / 哈希表的长度
也就是说,哈希表越满,负载因子越大。
数组、链表、Hash的优缺点:
1、数组是将元素在内存中连续存放。
链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。
2、数组必须事先定义固定的长度,不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费。
链表动态地进行存储分配,可以适应数据动态地增减的情况。
3、(静态)数组从栈中分配空间, 对于程序员方便快速,但是自由度小。
链表从堆中分配空间, 自由度大但是申请管理比较麻烦。
数组和链表在存储数据方面到底孰优孰劣呢?根据数组和链表的特性,分两类情况讨论。
一、当进行数据查询时,数组可以直接通过下标迅速访问数组中的元素。而链表则需要从第一个元素开始一直找到需要的元素位置,显然,数组的查询效率会比链表的高。
二、当进行增加或删除元素时,在数组中增加一个元素,需要移动大量元 素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样,如果想删除一个元素,需要移动大量元素去填掉被移动的元素。而链表只需改动元素中的指针即可实现增加或删除元素。
那么,我们开始思考:有什么方式既能够具备数组的快速查询的优点又能融合链表方便快捷的增加删除元素的优势?HASH呼之欲出。
所谓的hash,简单的说就是散列,即将输入的数据通过hash函数得到一个key值,输入的数据存储到数组中下标为key值的数组单元中去。
我们发现,不相同的数据通过hash函数得到相同的key值。这时候,就产生了hash冲突。解决hash冲突的方式有两种。一种是挂链式,也叫拉链法。挂链式的思想在产生冲突的hash地址指向一个链表,将具有相同的key值的数据存放到链表中。另一种是建立一个公共溢出区。将所有产生冲突的数据都存放到公共溢出区,也可以使问题解决。
hash表其实是结合了数组和链表的优点,进行的折中方案。平衡了数组和链表的优缺点。hash的具体实现有很多种,但是需要解决冲突的问题。
不相同的数据通过hash函数得到相同的key值。这时候,就产生了hash冲突。解决hash冲突的方式有两种。一种是挂链式,也叫拉链法。挂链式的思想在产生冲突的hash地址指向一个链表,将具有相同的key值的数据存放到链表中。另一种是建立一个公共溢出区。将所有产生冲突的数据都存放到公共溢出区,也可以使问题解决。
树(Tree)
二叉树的前序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* public var val: Int
* public var left: TreeNode?
* public var right: TreeNode?
* public init(_ val: Int) {
* self.val = val
* self.left = nil
* self.right = nil
* }
* }
*/
class Solution {
func preorderTraversal(_ root: TreeNode?) -> [Int] {
var res: [Int] = []
var stack: [TreeNode] = []
var node: TreeNode? = root
while node != nil || !stack.isEmpty {
if node != nil {
res.append(node!.val)
stack.append(node!)
node = node?.left
} else {
node = stack.removeLast().right
}
}
return res
}
}
二叉树的中序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* public var val: Int
* public var left: TreeNode?
* public var right: TreeNode?
* public init(_ val: Int) {
* self.val = val
* self.left = nil
* self.right = nil
* }
* }
*/
class Solution {
func inorderTraversal(_ root: TreeNode?) -> [Int] {
var res: [Int] = []
var stack: [TreeNode] = []
var node: TreeNode? = root
while node != nil || !stack.isEmpty {
if node != nil {
stack.append(node!)
node = node?.left
} else {
let _node = stack.removeLast()
res.append(_node.val)
node = _node.right
}
}
return res
}
}
二叉树的后序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* public var val: Int
* public var left: TreeNode?
* public var right: TreeNode?
* public init(_ val: Int) {
* self.val = val
* self.left = nil
* self.right = nil
* }
* }
*/
class Solution {
func postorderTraversal(_ root: TreeNode?) -> [Int] {
var res: [Int] = []
var stack: [TreeNode] = []
var node: TreeNode? = root
var last: TreeNode? = root
while node != nil || !stack.isEmpty {
while node != nil {
stack.append(node!)
node = node?.left
}
node = stack.last!
if node?.right == nil || node?.right?.val == last?.val {
last = stack.last!
res.append(stack.removeLast().val)
node = nil
} else {
node = node?.right
}
}
return res
}
}
二叉树的层次遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* public var val: Int
* public var left: TreeNode?
* public var right: TreeNode?
* public init(_ val: Int) {
* self.val = val
* self.left = nil
* self.right = nil
* }
* }
*/
class Solution {
func levelOrder(_ root: TreeNode?) -> [[Int]] {
var res: [[Int]] = []
var stack: [TreeNode] = []
guard let root = root else {
return []
}
stack.append(root)
while !stack.isEmpty {
var level: [Int] = []
for _ in 0..<stack.count {
let removeNode = stack.removeFirst()
level.append(removeNode.val)
if let leftNode = removeNode.left {
stack.append(leftNode)
}
if let rightNode = removeNode.right {
stack.append(rightNode)
}
}
res.append(level)
}
return res
}
}
红黑树
堆和栈 (heap & Stack)
objective-c 对象所占内存总是分配在“堆空间”,并且堆内存是由你释放的,即release。 栈是由编译器管理自动释放的,在方法中(函数体)定义的变量通常在栈内。
1.栈区(stack):由编译器自动分配释放,存放函数的参数值,局部变量等值。其操作方式类似于数据结构中的栈。 2.堆区(heap):一般由程序员分配释放,若程序员不释放,则可能会引起内存泄漏。注 堆和数据结构中的堆栈不一样,其类似于链表。
栈是一个用来存储局部和临时变量的存储空间。在现代操作系统中,一个线程会分配一个栈. 当一个函数被调用,一个stack frame(栈帧)就会被压到stack里。里面包含这个函数涉及的参数,局部变量,返回地址等相关信息。当函数返回后,这个栈帧就会被销毁。而这一切都是自动的,由系统帮我们进行分配与销毁。对于程序员来说,我们无须自己调度。
堆从本质上来说,程序中所有的一切都在内存中(有些东西是不在堆栈中的,但在这篇文章中我们不作讨论)。在堆上,我们可以任何时候分配内存空间以及释放销毁它。你必须显示的请求在堆上分配内存空间,如果你不使用垃圾回收机制,你必须显示的去释放它。这就是在你的函数调用前需要完成的事情。简单来说,就是malloc与free。
通常以这种方式创建对象: NSObject *obj = [[NSObject alloc] init]; 系统会在栈上存储obj这个指针变量,它所指的对象在堆中。通过[NSObject alloc]系统会为其在堆中开辟一块内存空间,并为其生成NSObject所需内存结构布局。
栈对象: 优点:1.高速,在栈上分配内存是非常快的。 2.简单,栈对象有自己的生命周期,你永远不可能发生内存泄露。因为他总是在超出他的作用域时被自动销毁了 缺点:栈对象严格的定义了生命周期也是其主要的缺点,栈对象的生命周期不适于Objective-C的引用计数内存管理方法。 在objective-c中只支持一个类型对象:blocks。 关于在block中的对象的生命周期问题。出现这问题的原因是,block是新的对象,当你使用block时候,如果你想对其保持引用,你需要对其进行copy操作,(从栈上copy到堆中,并返回一个指向他的指针),而不是对其进行retain操作 堆对象: 优点:可以自己控制对象的生命周期。
缺点:需要程序员手动释放,容易造成内存泄漏。
1、栈创建,只要栈的剩余空间大于stack 对象申请创建的空间,操作系统就会为程序提供这段内存空间,否则将报异常提示栈溢出。 2、堆创建,操作系统对于内存堆(heap) 段是采用链表进行管理的。操作系统有一个记录空闲内存地址的链表,当收到程序的申请时,会遍历链表,寻找第一个空间大于所申请的heap 节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。 3.例子:NSString(NSArray) 的对象就是stack 中的对象,NSMutableString (NSMutableArray)的对象就是heap 中的对象。前者创建时分配的内存长度固定且不可修改;后者是分配内存长度是可变的,可有多个owner, 适用于计数管理内存管理模式。 4、区别`堆(heap)和栈(stack)区别
(1).申请方式和回收方式
栈区(stack) :由编译器自动分配并释放 堆区(heap):由程序员分配和释放
(2).申请后系统的响应 栈区(stack):存储每一个函数在执行的时候都会向操作系统索要资源,栈区就是函数运行时的内存,栈区中的变量由编译器负责分配和释放,内存随着函数的运行分配,随着函数的结束而释放,由系统自动完成。只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。 堆区(heap):操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
(3).申请大小的限制 栈区(stack):栈是向低地址扩展的数据结构,是一块连续的内存的区域,能从栈获得的空间较小(2M)。 堆区(stack):堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存,空间比较大
(4).申请效率的比较 栈区(stack):由系统自动分配,速度较快。但程序员是无法控制的。 堆区(stack):是由alloc分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
(5).分配方式的比较 栈区(stack):有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloc函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。 堆区(stack):堆都是动态分配的,没有静态分配的堆。 (6).分配效率的比较 栈区(stack):栈是操作系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。 堆区(stack):堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。`