iOS关键词总结
2023-09-16 » 自我成长如果你不知道你接下来需要补充学习哪一部分知识,梳理一下自己认识的关键词吧。
App启动
- 热启动
- 冷启动
- 后台回前台
苹果本身的优化
- 启动闭包(iOS13 dyld3)
- 预热(iOS 15)
一般启动度量都用冷启动的耗时,premain + postmain的方式,
现在由于苹果本身的优化,premain的关注度就相对降低,而且预热的出现,导致premain出现较多脏数据,长达20分钟的premain
具体启动流程
- 细分从点击AppIcon到App启动:
1、 SpringBoad复制进程,loadMachine加载Mach-o(parse_machfile) command读取
2、进行__TEXT,__DATA的映射,加载UUID,创建主线程,代码签名验证
3、加载动态链器(dyld2、dyld3(iOS13)、dyld4(iOS16))
3、dyld 加载过程的三个阶段(system interface -> Runtime Initializer -> main)
4、main后阶段
dyld流程
第一阶段:system interface
1- 设置环境变量
2- loadDyldCache 共享库缓存
比如UIKit等系统动态库 都是通过dyld从共享缓存载入
3- 实例化主程序 instantiateFromLoadedImage
加载可执行文件并生成一个ImageLoader实例对象(读取可执行文件头信息 )
4- 加载插入的动态库 (耗时)
5- 链接主程序
6- 链接插入的动态库 (耗时)
按从主程序根节点的依赖关系递归Bind
ImageLoader::link - recursiveRebase、recursiveBind
7- 弱符号绑定(优先非懒加载、弱符号,懒加载符号在第一次调用后再绑定)
__attribute__ ((weak))
ImageLoader::link - weakBind
8 - 主程序初始化 initializeMainExecutable
递归初始化,先初始化依赖的动态库,再初始化主程序。
深度遍历直到对应的image没有依赖时也就是libsystem.dylib的时候,第一次初始化里面触发dyld注册函数回调
链路如下:
doModInitFunctions - libsystem_initializer - libdispatch_init - _objc_init - _dyld_objc_callbacks_v1(dyld注册回调函数)
dyld注册回调函数:
其中包含(map_images,load_images,unmap_image)三部分
- map_image() 管理所有的符号(class、protocol、selector、category)
- 初次加载会初始化
- 初始化 gdb_objc_realized_classes 所有类总表
- sel_init namedSelectors表初始化
- SideTablesMap.init 初始化引用计数、weak表等
- _objc_associations_init AssociationsManager init 关联对象表
- AutoreleasePoolPage init
- 核心逻辑 _read_images
- 修复SEL:将所有SEL(mach-o里的__objc_selrefs中的)注册到namedSelectors表初始化表中,rebase成真实内存地址
- 将所有class(mach-o里的__objc_classlist)执行 readClass
- 返回一个Class指针
- // 将 cls 加入到 gdb_objc_realized_classes 表里面去
- // 将 cls 插入到 allocatedClasses 表里面去
- 修复class映射:将所有class(__objc_classlist)remapClassRef,rebase成真实内存地址
- objc_msgSend_fixup 修复旧的函数指针调用遗留
- 将所有protocol(mach-o里的__objc_protolist)执行 readProtocol
- 读取然后存入protocol_map 哈希表
- 修复协议映射 remapProtocolRef,rebase成真实内存地址
- load_categories_nolock 初始化分类
- 有判断条件:didInitialAttachCategories。需要等第一个loadImage执行过后这里才能执行
- attachCategories
- 最重点:实现所有非懒加载类,realizeClassWithoutSwift 类的初始化
- class_ro_t class_rw_t 构建,递归构建父类、元类
- 绑定父子类、元类关系
- 最重点:methodizeClass 方法序列表
- 将 ro 里面的方法、属性、协议附加到 rw 里面去
- unattachedCategories 附加分类 (方法、属性、协议)
- 附加方式attachLists,旧的从addCount开始存放,新的从首位开始存放 (先移动旧的,然后插入新的),所以分类方法在前
- fixupMethodList 方法SEL 修正、排序
- load_image() 查找所有的load方法,然后执行
- prepare_load_methods
- schedule_class_load 通过类初始化标记位 递归搜集load方法
- add_class_to_loadable_list 存放在全局 loadable_classes线性表,存放类型为loadable_class结构体(Class cls -> IMP)
- add_category_to_loadable_list 存放在全局 loadable_categories线性表,存放类型为loadable_category结构体(Category cat -> IMP)
- // List of classes that need +load called (pending superclass +load)
- // This list always has superclasses first because of the way it is constructed
- call_load_methods
- (*load_method)(cls, SEL_load); 不走消息发送,直接走指针调用
- call_class_loads 按标记位循环调用 loadable_classes 表中类的 IMP
- call_category_loads 按标记位循环调用 loadable_categories 表中类的 IMP
- 分类的加载 loadAllCategories
- load_categories_nolock : 条件 didInitialAttachCategories & didCallDyldNotifyRegister 只有dyld回调这次才会走
- attachCategories 方法、属性、协议拷贝到主类 rwe
9 - doModInitFunctions - static initializer 初始化C&C++的静态化变量,然后调用 __attribute__((contrutor)) 函数
10 - getEntryFromLC_MAIN 返回main函数入口
dyld不同版本差异
dyld2(步骤都是在进程内完成的)
- dyld_start(rebaseDyld 数据重定位【ASLR原因】、其他配置)
- 解析 Mach-o Header文件
- 根据头文件信息查找依赖项
- 映射Mach-o到内存
- 执行符号查找(比如用到的外部函数等需要重新指定地址)
- Bind & Rebase 符号绑定和地址重定位【ASLR原因】
- Run initializers
dyld3 (通过启动闭包机制提高启动速度,包括进程内外三部分)
- 进程外的Mach-o解析器
包括 解析Mach-o头文件、依赖项查找、符号查找,并把这部分结果封装为闭包写入磁盘
- 进程内的启动闭包运行器
包括 解析验证启动闭包、映射Mach-o、Bind&Rebase、Run initializers
- 启动闭包缓存服务
在App安装的时候就会尝试构建启动闭包缓存
dyld4: 采用pre-build + just-in-time 预构建/闭包+实时解析的双解析模式, 将根据缓存有效与否选择合适的模式进行解析, 同时也处理了闭包失效时候需要重建闭包的性能问题
分类处理全程跟踪
三处 attachedCategories
1、_read_images 的 discover categories时候 load_categories_nolock
2、_read_images 的 非懒加载类实现的时候 realizeClassWithoutSwift
3、load_image 的 loadAllCategories 时候
这里还区分懒加载和非懒加载类,主类懒加载 or 不懒加载,分类懒加载 or 不懒加载
程序在编译完成之后,会将所有的Category转换成 struct category_t (含有属性列表、实例、类方法列表、协议列表)最终会合并到主类的rwe结构里的各自表中
1、分类的方法列表附加在列表前面,分类之间的顺序取决于分类文件编译顺序 (每个主类、每个分类的方法list顺序还是正常的)
2、其中方法列表在附加之前会进行排序,方便后续方法查询的时候使用二分查找加快速度(fixupMethodList Sort by selector address.)
3、category里和主类的同名方法并不是覆盖,而是由于category中的方法因为附加到list是在前面,而主类的方法是被放在后面,而方法查找是从第一个方法开始查找,直到找到第一个同名的方法,则将该方法返回,所以会优先调用category的方法而忽略主类中的方法(不同cateory中的同名方法则是看哪个category文件最后编译,最后编译的会被调用)
新数组的构建,老的往后挪需要的n个位置,从0到n的位置留给新加进来的内容
for (int i = oldCount - 1; i >= 0; i--)
newArray->lists[i + addedCount] = array()->lists[i];
for (unsigned i = 0; i < addedCount; i++)
newArray->lists[i] = addedLists[i];
ro、rw的区别
ro、rw的区别,设计的目的是为了保存更多的clean memory
旧逻辑:
1、当一个类被装载到内存中时就会初始化一个class_rw_t结构
2、把class_ro_t结构中方法、属性、协议数据复制到class_rw_t
3、方法查找等就直接从 class_rw_t 查找
问题:
class_rw_t属于dirty memory,在程序运行的时候这块内存就必须一直存在,但是大概90%的类并不需要对其中的Methods进行修改,所以这部分的内存其实就是属于浪费
解决:于是苹果拆分出来一个新的数据结构:class_rw_ext_t
新逻辑:
1、当一个类被装载到内存中时就会初始化一个class_rw_t结构,但是不会复制ro_t的方法、属性、协议
2、懒加载,需要的时候再开辟 class_rw_ext_t 存放 ro_t的方法、属性、协议
3、方法查找 有rwe就查rwe 没有 就查 ro
- class_ro_t 不可变原始空间,原类的方法、属性、协议列表等
- class_rw_t 运行时脏内存
- class_rw_ext_t 方法、属性、协议 (2020WWDC)
懒加载类的加载全程跟踪
我们前面区分懒加载非懒加载(实现了+load的方法属于非懒加载)
懒加载类情况是数据加载推迟到第⼀次消息的时候
- lookUpImpOrForward -> realizeClassMaybeSwiftMaybeRelock -> realizeClassWithoutSwift -> methodizeClass
ASLR
在iOS系统中打开一个App的时候是会将App的二进制数据从硬盘copy到内存里,那么这时候二进制数据就会对应一个内存地址,由于考虑安全等因素的问题,内存的地址都是由虚拟缓存地址替代,而且地址的起始位置都是动态的,每次启动的时候都会不一样,这个技术就是ASLR。所以当DYLD加载MachO的时候最先一步要做的就是对数据进行重定位
实际运行地址 = 静态的基地址 + ASLR偏移
Mach-o文件
Header 的最开始是 Magic Number,表示这是一个 Mach-O 文件,除此之外还包含一些 Flags,这些 flags 会影响 Mach-O 的解析。
Load Commands 存储 Mach-O 的布局信息,比如 Segment command 和 Data 中的 Segment/Section 是一一对应的。除了布局信息之外,还包含了依赖的动态库等启动 App 需要的信息。
Data 部分包含了实际的代码和数据,Data 被分割成很多个 Segment,每个 Segment 又被划分成很多个 Section,分别存放不同类型的数据。
标准的三个 Segment 是 TEXT,DATA,LINKEDIT,也支持自定义:
TEXT,代码段,只读可执行,存储函数的二进制代码(__text),常量字符串(__cstring),Objective C 的类/方法名等信息
DATA,数据段,读写,存储 Objective C 的字符串(__cfstring),以及运行时的元数据:class/protocol/method…
LINKEDIT,启动 App 需要的信息,如 bind & rebase 的地址,代码签名,符号表…
Link Map File
Rebase & Bind
由于ASLR机制,Rebase 和 Bind的作用就是修正地址偏移
Rebase:修复内部指针。这是因为 Mach-O 在 mmap 到虚拟内存的时候,起始地址会有一个随机的偏移量 slide,需要把内部的指针指向加上这个 slide。
Bind:修复外部指针。这个比较好理解,因为像 printf 等外部函数,只有运行时才知道它的地址是什么,bind 就是把指针指向这个地址。
寄存器
二进制重排、Page In、虚拟内存
App使用内存时虚拟内存,一块虚拟内存会和一块物理内存在表上记录地址映射关系
当读取虚拟内存,对应的物理内存没有需要的数据的时候就会执行 Page In
1、系统阻塞该进程
2、将磁盘中对应Page的数据加载到内存
3、把虚拟内存指向物理内存
iOS ipone6S以上是 16K一页内存页,映射一页在1微秒到0.8毫秒之间。
iOS13 之前读Text段的页还需要解密、签名验证耗时,这个在iOS13系统之后优化了
减少Page In就可以减少耗时
低版本系统可以通过 ld 的-rename_section,把 TEXT 段中的内容,比如字符串移动到其他的段(启动路径上难免会读很多字符串),从而规避这个解密的耗时
高版本尽量避免Page In,也就是进行二进制重排
页缺失:当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,MMU发出的中断,就会触发下面的操作
- 把磁盘中的数据写到内存的过程是Page in
- 把内存中的数据写到磁盘的过程是Page out
Hook 所有的+Load方法
GNU C __attribute__ 机制
__attribute__((constructor)) 中执行,
因为它执行的时候 +Load方法已经ready
constructor修饰,让系统执行main()函数之前调用函数
destructor修饰,让系统在main()函数退出或者调用了exit()之后
引用计数
1、Tagged Pointer(64位系统中节约内存)
iOS结构:(TaggedPointer标识位 + 类标识 + 数据 + 数据类型)
- 64位下 一个指针8字节,指向一个NSNumber(值8 字节 + isa8字节)共24字节。
- TaggedPointer 直接把值放在指针中存放,共8字节
- Tagged Pointer专门用来存储小的对象,例如NSNumber和NSDate
- Tagged Pointer指针的值不再是地址了,而是真正的值。所以,实际上它不再是一个对象了,它只是一个披着对象皮的普通变量而已。所以,它的内存并不存储在堆中,也不需要malloc和free。
- 要通过object_getClasss访问,避免直接访问,内部都做了兼容,包括objc_msgSend、weak等情况,避免直接使用isa,因为不是真对象,没有isa
- 在内存读取上有着3倍的效率,创建时比以前快106倍。
2、nonpointer isa (64位系统节约内存,isa除了类对象信息还包括其他)
isa_t
- has_sidetable_rc 是否用sidetable存放引用计数
- bits 存储对象使用过程中的其他信息
- Class cls 指向类对象
- extra_rc 不用sidetable的时候存放引用计数的地方(10以内)
3、存放引用计数的结构
SideTablesMap 哈希桶:所有对象,内存地址为key
- SideTable 哈希表:内存地址为key,
- 自旋锁 非公平 unfair 锁
- RefcountMap 引用计数表
- weak_table_t 弱引用表
weak
1、特点
- 不会增加指向对象的引用计数 (规避循环引用)
- 指向对象释放后,变量会自动置 nil (规避野指针访问错误)
2、关键数据结构认识
- weak_table_t (key由处理对象内存地址生成,value是weak_entry_t)
- weak_entry_t *weak_entries;
- 其他辅助hash的变量
- weak_entry_t
- referent 实际对象地址的包装对象,一个封装用于解决内存泄漏
- 以下联合都是存放weak指针
- referrers 大于4个用这个hash表
- inline_referrers 小于4个用这个数组
3、关键流程认识
- weak指针获取
1、通过被指向对象的地址获取SideTables -> SideTable -> weak_table_t
2、通过对象地址获取weak_table_t中的referrer(weak指针)
- weak指针存放
1、通过对象地址 + weak指针地址触发storeWeak
2、检查指针是否有旧指向,检查对象是否支持weak、是否是Taggedgpoint、是否正在释放
3、释放指针旧指向
4、检查是否已存在对象的weak_entry
5、插入已有weak_entry或新建weak_entry并插入weak_table
- weak指针置空
1、dealloc - object_dispose - clearDeallocating - weak_clear_no_lock 对象的销毁会触发weak清理
2、检查释放对象是否存在weak引用
3、遍历weak_entry -> referrers 中的所有weak指针并指向nil
4、weak_entry_remove 从weak_table移除weak_entry
4、关键函数认识
- objc_initWeak
- 参数1:location :__weak指针的地址,存储指针的地址,这样便可以在最后将其指向的对象置为nil
- 参数2:所引用的对象
- objc_storeWeak (置 nil 也是直接用的这个函数)
- 除开上面init的参数,还多3个
- 存放的这个weak指针是否存在旧指向
- 存放的这个weak指针是否需要新指向
- 被指向对象是否正在释放流程
- weak_register_no_lock 新对象注册
- weak_entry_for_referent 是否已存在检查 weak_entry_t
- 存在,append_referrer 到 entry
- 不存在,newEntry -> weak_entry_insert 新建entry并插入 weak_entry_insert
- weak_unregister_no_lock 旧对象解除
1、按referent在weak_table_t中找到entry
2、移除对应referrer(weak指针)
3、判断是否entry已经空了,没有weak指针了
4、weak_entry_remove 在weak_table_t中移除entry
- weak_clear_no_lock
- weak_entry_for_referent 是否已存在检查 weak_entry_t
- 遍历weak_entry -> referrers 中的所有weak指针并指向nil
- 如果weak指针数量为空,weak_entry_remove 移除实例
iOS内存分区
- 代码段
代码段主要存储编译后的代码
- 数据段
字符串常量
初始化完成的全局变量和静态变量
未初始化的全局变量和静态变量
- 堆区
内存地址分配由低到高
通过 alloc malloc calloc 进行内存分配
- 栈区
内存地址分配由高到低
函数调用开销,比如局部变量
- 内核区
内存对齐
内存对齐的目的:
1、处理器内存访问提效(cpu以块的方式读取内存,不对齐的开销大,得分两次读取)
64位系统下(CF requires all objects be at least 16 bytes.)
对象内存申请为8的倍数,最小16 if (size < 16) size = 16;
struct TTStruct1 {
char a; //1字节 -- 占据0字节
double b; //8字节 -- 占据8-15字节
int c; //4字节 -- 占据16-19字节
short d; //2字节 -- 占据20-22字节
} MyStruct1; //共22字节,但22不是8的倍数,则+2,因为24是8的倍数
规则一:数据成员的对齐规则可以理解为min(m, n) 的公式, 其中 m表示当前成员的开始位置, n表示当前成员所需要的位数。如果满足条件 m 整除 n (即 m % n == 0), n 从 m 位置开始存储, 反之继续检查 m+1 能否整除 n, 直到可以整除, 从而就确定了当前成员的开始位置
规则二:如果⼀个结构⾥有某些结构体成员,则结构体成员要从其内部最⼤元素⼤⼩的整数倍地址开始存储
规则三:结构体的总体大小,即sizeof的結果,必须是其內部最大成員的整數倍,不足的需要补齐
系统在属性上会自动内存对齐优化 属性重排 iOS堆内存 16字节对齐
16、alloc、init
- alloc
1、instanceSize 确定内存分配大小
2、calloc分配内存 ->obj
3、给obj 构建isa指针 绑定isa和对象
- init
只是返回了对象
NSObject *obj = [[NSObject alloc] init]占有多少空间?
isa 8字节,但是最小16字节,所以返回16字节,其中8字节空的
new 相当于 alloc + init
inline size_t instanceSize(size_t extraBytes) const {
if (fastpath(cache.hasFastInstanceSize(extraBytes))) {
return cache.fastInstanceSize(extraBytes);
}
size_t size = alignedInstanceSize() + extraBytes;
// CF requires all objects be at least 16 bytes.
if (size < 16) size = 16;
return size;
}
iOS 内存机制
mmap(一种内存映射文件的方法)
- 将一个文件或者其它对象映射到进程的内存地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对应关系
- 映射成功后,进程可以通过操作指针操作内存,系统自动回写脏内存到文件,相当于直接操作了文件,而不需要走read,write等高消耗操作
- 映射关系中也会有内存对齐操作
- 优势:内存占用少(大文件读取),读写速度快,长时间读写文件场景
扩展
read,write等基础操作,由于页缓存机制,导致,从磁盘拷贝到页缓存(内核空间),由于进程不能直接访问,还得拷贝到用户空间
mmap只是建立了磁盘地址和内存区域地址的映射,无需文件拷贝。如果发现需要使用时,内容还没导入用户内存,只需直接从磁盘拷贝到用户内存空间即可,最多也就是一次拷贝操作
问题:
大文件读取还是会占用过量的虚拟内存
内存页、页缓存机制、MMU
虚拟内存到物理内存映射的最小单位就是页,iOS ipone6S以上是 16K一页内存页 之前是4K一页
虚拟内存的作用就是可以解决
- 物理内存小,比如我申请不到连续的固定大小内存,虚拟内存可以映射多个不连续片段返回进程
MMU:内存管理单元
- 完成虚拟地址转换为物理地址的硬件,包含在CPU中
- 借助存放在内存中的页表来动态翻译虚拟地址为物理地址
页缺失:当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,MMU发出的中断,就会触发下面的操作
- 把磁盘中的数据写到内存的过程是Page in
- 把内存中的数据写到磁盘的过程是Page out
MMKV 和 自己实现一个nsuserdefault
FastImageCache
17、assign
assign一般用来修饰值类型,存储在栈空间的属性,由系统管理其内存生命周期
assign引用对象编译不报错,但是可能出生野指针访问异常
assign没有强引用,当修饰对象被释放后,指针还在,访问指针可能出现野指针
weak只能修饰对象,修饰基础类型会编译错误
18、iOS关键词 访问控制
@private 作用范围只能在自身类
@protected 作用范围在自身类和继承自己的子类,什么都不写,默认是此属性。
@public 作用范围最大,在任何地方
swift
open 跨模块可见,可修改可继承
public 跨模块可见,不可修改
internal 模块内可见级别 默认
fileprivate 文件内私有
private 类中私有
block的本质
源码:libclosure 库
struct __main_block_impl_0 {
struct __block_impl impl;
__main_block_impl_0(void *fp, int flags=0) {
impl.isa = 0/*&_NSConcreteStackBlock*/;
impl.Size = sizeof(__main_block_impl_0);
impl.Flags = flags;
impl.FuncPtr = fp;
}
};
struct __block_impl {
void *isa;
int Flags;
int Size;
void *FuncPtr;
};
总结:一个包装类,带一个block结构体属性和一个构造函数
从__main_block_impl_0构造函数分析
1、block 是对象,一个结构体对象,他有isa指针
2、FuncPtr 指向方法体的实现
3、isa为 _NSConcreteStackBlock 类型
可以通俗理解成 block是一个继承自_NSConcreteStackBlock的类
clang转译写的block
普通block
// 声明一个 block 类型变量 myBlock,指向一个新定义的 Block
void (^myBlock)(void) = ^{
NSLog(@"Hello world!");
};
// 调用此 block
myBlock();
------------------- 通过clang编译成c++ -------------------
// 定义 Block
void (*myBlock)(void) = ((void (*)())&__main_block_impl_0((void *)__main_block_func_0, &__main_block_desc_0_DATA));
// 调用 Block
((void (*)(__block_impl *))((__block_impl *)myBlock)->FuncPtr)((__block_impl *)myBlock);
有外层变量访问的block,截获
// 定义局部变量 (为了测试的更完整,我增加了一个对象)
int a = 10;
id obj = [[NSObject alloc] init];
// 声明一个 block 类型变量 myBlock,指向一个新定义的 Block
void (^myBlock)(void) = ^{
NSLog(@"Hello world! %d, %@", a, obj);
};
// 调用此 block
myBlock();
------------------- 通过clang编译成c++ -------------------
// 定义局部变量与生成对象
int a = 10;
id obj = ((NSObject *(*)(id, SEL))(void *)objc_msgSend)((id)((NSObject *(*)(id, SEL))(void *)objc_msgSend)((id)objc_getClass("NSObject"), sel_registerName("alloc")), sel_registerName("init"));
// 定义 Block
void (*myBlock)(void) = ((void (*)())&__main_block_impl_0((void *)__main_block_func_0, &__main_block_desc_0_DATA, a, obj, 570425344));
// 调用 Block
((void (*)(__block_impl *))((__block_impl *)myBlock)->FuncPtr)((__block_impl *)myBlock);
block外层变量访问的实现
1、本质是编译器给处理了,往包装类中构造了两个成员变量,就是我们访问的局部变量
2、构造函数也增加了两个相应的参数
3、所以发生自动截取的问题,只有引用对象才不被截取
有外层变量访问的block,__block修饰不截获
// 定义 block 变量
__block id obj = [[NSObject alloc] init];
__block int a = 10;
// 声明一个 block 类型变量 myBlock,指向一个新定义的 Block
void (^myBlock)(void) = ^{
obj = [[NSObject alloc] init];
a = 20;
};
// 调用此 block
myBlock();
------------------- 通过clang编译成c++ -------------------
// 对应于:__block id obj = [[NSObject alloc] init];
__attribute__((__blocks__(byref))) __Block_byref_obj_0 obj =
{
(void*)0,
(__Block_byref_obj_0 *)&obj,
33554432,
sizeof(__Block_byref_obj_0),
__Block_byref_id_object_copy_131,
__Block_byref_id_object_dispose_131,
((NSObject *(*)(id, SEL))(void *)objc_msgSend)((id)((NSObject *(*)(id, SEL))(void *)objc_msgSend)((id)objc_getClass("NSObject"), sel_registerName("alloc")), sel_registerName("init"))
};
// 对应于:__block int a = 10;
__attribute__((__blocks__(byref))) __Block_byref_a_1 a =
{
(void*)0,
(__Block_byref_a_1 *)&a,
0,
sizeof(__Block_byref_a_1),
10
};
// Block 定义
void (*myBlock)(void) = ((void (*)())&__main_block_impl_0((void *)__main_block_func_0, &__main_block_desc_0_DATA, (__Block_byref_obj_0 *)&obj, (__Block_byref_a_1 *)&a, 570425344));
// 调用 block 方法
((void (*)(__block_impl *))((__block_impl *)myBlock)->FuncPtr)((__block_impl *)myBlock);
__block的原理
__block的修饰,把原变量进行的包装,比如int a,包装为了 __Block_byref_a_1
struct __Block_byref_obj_0 {
void *__isa;
__Block_byref_obj_0 *__forwarding;
int __flags;
int __size;
void (*__Block_byref_id_object_copy)(void*, void*);
void (*__Block_byref_id_object_dispose)(void*);
id obj; // 封装类中的
};
struct __Block_byref_a_1 {
void *__isa;
__Block_byref_a_1 *__forwarding;
int __flags;
int __size;
int a;
};
源码结构如上,__Block_byref_a_1 中的forwarding指针指向的是原本的变量a的地址
所以内部修改也就修改的是原本变量a
对象类型的变量还多了一个copy 一个 dispose的方法
1、copy的作用涉及到block的拷贝
block根据所在内存可归为以下三种类型
NSConcreteStackBlock | 栈区 | (访问局部变量,离开方法作用域就会销毁)
NSConcreteGlobalBlock | 数据区 | (定义在全局 访问静态变量或者不访问外部变量的)
NSConcreteMallocBlock | 堆区 | (赋值操作会自动拷贝到堆)
// 定义一个全局 Block
void (^globalBlock)(void) = ^{ printf("globalBlock\n", ); };
int main(int argc, const char * argv[]) {
int a = 1;
static int b = 2;
void(^localBlock)(void) = ^(void) {
NSLog (@"访问局部变量 localBlock % d", a);
};
void(^staticBlock)(void) = ^(void) {
NSLog (@"访问静态变量 staticBlock % d", b);
};
void(^paramBlock)(NSString *) = ^(NSString *inputStr) {
NSLog (@"只访问入参 paramBlock %@", inputStr);
};
globalBlock();
localBlock();
staticBlock();
paramBlock(@"c");
NSLog(@"globalBlock:%@", globalBlock);
NSLog(@"localBlock:%@", localBlock);
NSLog(@"staticBlock:%@", staticBlock);
NSLog(@"paramBlock:%@", paramBlock);
NSLog(@"stackBlock:%@", ^{
NSLog (@"访问局部变量 stackBlock % d", a);
});
}
==> output:
globalBlock
访问局部变量 localBlock 1
访问静态变量 staticBlock 2
只访问入参 paramBlock hello
globalBlock:<__NSGlobalBlock__: 0x10b7f9138>
localBlock:<__NSMallocBlock__: 0x60000270e100>
staticBlock:<__NSGlobalBlock__: 0x10b7f9198>
paramBlock:<__NSGlobalBlock__: 0x10b7f91d8>
stackBlock:<__NSStackBlock__: 0x7ffee4406520>
堆拷贝的作用:Block 超出变量作用域后仍然可以使用
翻源码:_Block_copy
*dest = _Block_byref_copy(object);
block拷贝时,对应构造的成员变量也一起拷贝,forwarding指针的设计让指向依然正常
2、block对外部对象的持有 可能导致循环引用
由于block对对象的劫持是指针劫持,所以只要外部用的是weak,劫持到的指针也是weak修饰。就不会造成循环引用了
1、block要如何hook?
1、消息转发
强行将block的函数指针(invoke)强行指向_objc_msgForward,启动它的消息转发
在 NSInvocation 层转发
2、fishhook 去hook _Block_copy 函数,更换 invoke指向
struct Block_layout {
void * __ptrauth_objc_isa_pointer isa;
volatile int32_t flags; // contains ref count
int32_t reserved;
BlockInvokeFunction invoke;
struct Block_descriptor_1 *descriptor;
// imported variables
};
https://cloud.tencent.com/developer/article/1411339
4、OC Block 和 Swift闭包的区别
1、OC的block在编译的时候就执行了拷贝,swift 的闭包要到执行的时候才会发生拷贝,swift可以让他提前捕获
var i = 1
let closure = {
[i] in
print("closure \(i)")
}
加上[i] 就行
关联对象 AssociationsManager
动态添加属性
objc_setAssociatedObject(id object, const void *key, id value, objc_AssociationPolicy policy);
- 关键结构
- AssociationsManager
- AssociationsHashMap (装饰对象地址 - ObjectAssociationMap)
DenseMap<DisguisedPtr<objc_object>, ObjectAssociationMap>
- ObjectAssociationMap (属性key - ObjcAssociation)
DenseMap<const void *, ObjcAssociation>
- ObjcAssociation
- uintptr_t _policy;
- id _value;
1、一个对象就对应一个ObjectAssociationMap
2、ObjectAssociationMap中存储着多个此对象的关联属性的key以及ObjcAssociation
3、ObjcAssociation中存储着所有关联属性的value和policy策略
关联属性并不是存放在对象中,而是AssociationsManager在全局维护了一张哈希表
dealloc的时候回调用 - objc_destructInstance - _object_remove_associations 移除关联属性
runloop
哪些在用
1、检测卡顿
2、监听
// RunLoop的结构体定义
struct __CFRunLoop {
pthread_mutex_t _lock; // 访问mode集合时用到的锁
__CFPort _wakeUpPort; // 手动唤醒runloop的端口。初始化runloop时设置,仅用于CFRunLoopWakeUp,CFRunLoopWakeUp函数会向_wakeUpPort发送一条消息
pthread_t _pthread; // 对应的线程
CFMutableSetRef _commonModes; // 集合,存储的是字符串,记录所有标记为common的modeName
CFMutableSetRef _commonModeItems; // 存储所有commonMode的sources、timers、observers
CFRunLoopModeRef _currentMode; // 当前modeName
CFMutableSetRef _modes; // 集合,存储的是CFRunLoopModeRef
struct _block_item *_blocks_head; // 链表头指针,该链表保存了所有需要被runloop执行的block。外部通过调用CFRunLoopPerformBlock函数来向链表中添加一个block节点。runloop会在CFRunLoopDoBlock时遍历该链表,逐一执行block
struct _block_item *_blocks_tail; // 链表尾指针,之所以有尾指针,是为了降低增加block时的时间复杂度
};
struct __CFRunLoopSource {
CFRuntimeBase _base;
uint32_t _bits;
pthread_mutex_t _lock;
CFIndex _order; /* immutable */
CFMutableBagRef _runLoops;
union {
CFRunLoopSourceContext version0; /* immutable, except invalidation */
CFRunLoopSourceContext1 version1; /* immutable, except invalidation */
} _context;
};
typedef struct {
CFIndex version;
void * info;
const void *(*retain)(const void *info);
void (*release)(const void *info);
CFStringRef (*copyDescription)(const void *info);
Boolean (*equal)(const void *info1, const void *info2);
CFHashCode (*hash)(const void *info);
void (*schedule)(void *info, CFRunLoopRef rl, CFStringRef mode);
void (*cancel)(void *info, CFRunLoopRef rl, CFStringRef mode);
void (*perform)(void *info);
} CFRunLoopSourceContext;
typedef struct {
CFIndex version;
void * info;
const void *(*retain)(const void *info);
void (*release)(const void *info);
CFStringRef (*copyDescription)(const void *info);
Boolean (*equal)(const void *info1, const void *info2);
CFHashCode (*hash)(const void *info);
#if (TARGET_OS_MAC && !(TARGET_OS_EMBEDDED || TARGET_OS_IPHONE)) || (TARGET_OS_EMBEDDED || TARGET_OS_IPHONE)
mach_port_t (*getPort)(void *info);
void * (*perform)(void *msg, CFIndex size, CFAllocatorRef allocator, void *info);
#else
void * (*getPort)(void *info);
void (*perform)(void *info);
#endif
} CFRunLoopSourceContext1;
/* Run Loop Observer Activities */
typedef CF_OPTIONS(CFOptionFlags, CFRunLoopActivity) {
kCFRunLoopEntry = (1UL << 0), // 进入RunLoop
kCFRunLoopBeforeTimers = (1UL << 1), // 即将开始Timer处理
kCFRunLoopBeforeSources = (1UL << 2), // 即将开始Source处理
kCFRunLoopBeforeWaiting = (1UL << 5), // 即将进入休眠
kCFRunLoopAfterWaiting = (1UL << 6), //从休眠状态唤醒
kCFRunLoopExit = (1UL << 7), //退出RunLoop
kCFRunLoopAllActivities = 0x0FFFFFFFU
};
1、线程和runloop 一一对应,除了主线程,其他线程runloop要自行启用
2、获取线程runloop的方式就时CFRunLoopGetCurrent、currentRunLoop
3、一个source可以对应多个runloop
4、source1是由runloop和内核管理,mach port驱动。所以button的点击事件首先是由source1 接收IOHIDEvent,然后再回调 __IOHIDEventSystemClientQueueCallback() 内触发的source0,source0再触发的 _UIApplicationHandleEventQueue()。所以打印调用堆栈发现UIButton事件是source0触发的
5、CFRunLoopPerformBlock可将block 扔到指定runloop执行
6、runloop默认五个mode
kCFRunLoopDefaultMode、UITrackingRunLoopMode、kCFRunLoopCommonModes 是我们用到的
还有两个内部自用的,启动用一次的UIInitializationRunLoopMode、系统事件处理的GSEventReceiveRunLoopMode
7、runloop唤醒后的工作流程
kCFRunLoopBeforeTimers = (1UL << 1), // 即将开始Timer处理
kCFRunLoopBeforeSources = (1UL << 2), // 即将开始Source处理
- 处理加入runloop的 blocks
- 处理source0
- 处理加入runloop的 blocks
- 如果有就处理source1
(然后就是mach_msg等待重新被唤醒)
kCFRunLoopBeforeWaiting = (1UL << 5), // 即将进入休眠
kCFRunLoopAfterWaiting = (1UL << 6), //从休眠状态唤醒
- 如果有,处理timers
- 如果有,处理gcd async to mainqueue的block
- 如果有,处理source1
- 处理加入runloop的 blocks
runloop 事件执行判定规则
1、是否存在source1
runloopMode
当你调用 CFRunLoopRun() 时,线程就会一直停留在这个循环里,直到超时或被手动停止,该函数才会返回
1、一个CFRunLoopMode对象中有一个name,许多source0,许多source1,许多Timer,许多Observer和许多port 2、我们在下文会提到的kCFRunLoopDefaultMode就是mode的name,当你传入一个新的 mode name 但 RunLoop 内部没有对应 mode 时,RunLoop会自动帮你创建对应的 CFRunLoopModeRef 3、对于一个 RunLoop 来说,其内部的 mode 只能增加不能删除 4、source、timer、observer可以在多个mode中注册,但是只有RunLoop当前的currentMode下的source、timer、observer才可以运行
5、同时RunLoop有很多个mode,但是RunLoop在run的时候必须只能指定其中一个mode,运行起来之后,被指定的mode即为currentMode
7、切换mode实际是调用CFRunLoopRunSpecific 这个函数 切换时,会先退出 kCFRunLoopDefaultMode 的runloop循环,再重新进入 UITrackingRunLoopMode 的runloop循环
@autorelease、autoreleasepool
源码:
class AutoreleasePoolPage;
struct AutoreleasePoolPageData
{
AutoreleasePoolPage * const parent;
AutoreleasePoolPage *child;
AutoreleasePoolPage 是个双向链表结构,每个Page是栈结构
- push
- autoreleaseNewPage
- popPage
- page->releaseUntil(stop);
自动释放池工作原理:
1、与runloop挂钩,子线程如果没有开启runloop也无法生效
2、如果线程使用了自动释放池,会给runloop插入两个监听者
- kCFRunLoopEntry
(最高优先级监听者,保证回调发生最早,调用push创建释放池)
- kCFRunLoopBeforeWaiting | kCFRunLoopExit
(休眠前pop释放池子,同时push创建一个新池子,退出runloop时pop释放池子)
3、游标:POOL_BOUNDARY
- 区分不同的自动释放池,也就是不同的@autoreleasepool。调用push时,会传入POOL_BOUNDARY并返回一个地址,起到分割的作用
- 调用pop时会传入end地址,由于page本身是栈结构,所以从end开始调用释放直到游标位
- 如果是多个page,会从child page的最末尾开始调用释放,直到游标位置
3、多层嵌套@autoreleasepool
- 同一个池子,按不同@autoreleasepool 插入游标区分
@autoreleasepool {
btn = [[WSButton alloc]init];
[btn autorelease];
}
NSLog(@"要离开作用域了");
这种情况,btn离开autoreleasepool作用域就会销毁,不会等到运行循环监听触发
dealloc
1、dealloc中打印或调用 self的属性要注意已释放问题
NSCache 和 NSDictionary 的区别
1、NSDictionary
NSDictionary的key必须是支持NSCopying协议的对象
- key小而高效才能保证拷贝复制的时候没有太多负担
- 会保持对对象的强引用
- 没有自动释放逻辑
- 线程不安全
2、NSCache
- 收到系统内存告警时会自动释放对象 removeAllObject
- 线程安全
- 对key不是拷贝,只是强引用,没有拷贝消耗
3、NSMapTable
- NSMapTable可以对其key和value弱引用
[[NSMapTable alloc] initWithKeyOptions:NSPointerFunctionsStrongMemory valueOptions:NSPointerFunctionsWeakMemory capacity:0];
- 可以包含任意指针对象
4、NSPointerArray
- 和可变数组一样,有下标操作修改数组内容
- 可以插入或者删除nil,nil参与count计算
- 可以使用weak修饰成员,能使用weak的自动置空优势,比如持有监听者,自动释放置空,避免循环引用
- 可以for in遍历
5、NSProxy
实现了NSObject协议的抽象基类,是根类 不继承NSObject
- 模拟多继承
- 避免循环引用
//NSProxy 弱引用self
SDWeakProxy *weakProxy = [SDWeakProxy proxyWithTarget:self];
//CAdisplayLink 强引用proxy
_displayLink = [CADisplayLink displayLinkWithTarget:weakProxy selector:@selector(displayLinkDidRefresh:)];
-
NSTimer、CADisplayLink、dispatch_source_t 的优劣
1、NSTimer,使用简单,运行依赖Runloop没有Runloop无法使用,一次Runloop循环耗时长的时候会导致不精确
具体使用:
NSTimer *timer = [NSTimer timerWithTimeInterval:1 target:self selector:@selector(timerFired:) userInfo:nil repeats:YES];
[[NSRunLoop currentRunLoop] addTimer:timer forMode:NSRunLoopCommonModes];
[timer invalidate];
2、CADisplaylink,依赖屏幕刷新频率触发事件,最精确适合做UI刷新,屏幕刷新频率受影响时时间也会受影响,它的取值的精度只能是一次屏幕刷新的最小间隔,比如60HZ的屏幕,间隔为16.67ms
具体使用:
CADisplayLink *link = [CADisplayLink displayLinkWithTarget:self selector:@selector(takeTimer:)];
[link addToRunLoop:[NSRunLodop currentRunLoop] forMode:NSRunLoopCommonModes];
link.paused = !link.paused;
[link invalidate];
3、dispatch_source_t,不依赖runloop,获取的时间不精确而且使用麻烦
__block int countDown = 6;
/// 创建 计时器类型 的 Dispatch Source
dispatch_source_t timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, dispatch_get_main_queue());
/// 配置这个timer
dispatch_source_set_timer(timer, DISPATCH_TIME_NOW, 1 * NSEC_PER_SEC, 0);
/// 设置 timer 的事件处理
dispatch_source_set_event_handler(timer, ^{
//定时器触发时执行
if (countDown <= 0) {
dispatch_source_cancel(timer);
NSLog(@"倒计时 结束 ~~~");
}
else {
NSLog(@"倒计时还剩 %d 秒...", countDown);
}
countDown--;
});
/// 启动 timer
dispatch_active(timer);
4、dispatch_time_t
self.gcdTime = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, dispatch_get_global_queue(0, 0));
// 开始时间支持纳秒级别
dispatch_time_t start = dispatch_time(DISPATCH_TIME_NOW, (int64_t)2 * NSEC_PER_SEC);
// 2秒执行一次
uint64_t dur = (uint64_t)(2.0 * NSEC_PER_SEC);
// 最后一个参数是允许的误差,即使设为零,系统也会有默认的误差
dispatch_source_set_timer(self.gcdTime, start, dur, 0);
// 设置回调
dispatch_source_set_event_handler(self.gcdTime, ^{
NSLog(@"---%@---%@",[NSThread currentThread],self);
});
5、mach_absolute_time
使用mach内核级的函数可以使用mach_absolute_time()获取到CPU的tickcount的计数值,可以通过”mach_timebase_info”函数获取到纳秒级的精确度 。然后使用mach_wait_until(uint64_t deadline)函数,直到指定的时间之后,就可以执行指定任务了。
关于数据结构mach_timebase_info的定义如下:
struct mach_timebase_info {uint32_t numer;uint32_t denom;};
#include
#include
static const uint64_t NANOS_PER_USEC = 1000ULL;
static const uint64_t NANOS_PER_MILLISEC = 1000ULL * NANOS_PER_USEC;
static const uint64_t NANOS_PER_SEC = 1000ULL * NANOS_PER_MILLISEC;
static mach_timebase_info_data_t timebase_info;
static uint64_t nanos_to_abs(uint64_t nanos) {
return nanos * timebase_info.denom / timebase_info.numer;
}
void example_mach_wait_until(int seconds)
{
mach_timebase_info(&timebase_info);
uint64_t time_to_wait = nanos_to_abs(seconds * NANOS_PER_SEC);
uint64_t now = mach_absolute_time();
mach_wait_until(now + time_to_wait);
}
6、dispatch_async如果执行主队列任务会唤醒主线程,libDispatch 向主线程的 RunLoop 发送消息,RunLoop会被唤醒,并从消息中取得这个 block,并在回调里执行这个 block
dispatch_once 原理
简单类比可以比作一个带锁的懒加载单例写法
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
object = [[NSObject alloc] init];
});
源码
- dispatch_function_t 是包装后的blockInvoke,也就是执行指针
- dispatch_once_t 转成 dispatch_once_gate_t, 通过 os_atomic_load 判断是否执行标记过
- 如果执行过就return,如果没有就进行原子性操作尝试 _dispatch_once_gate_tryenter 执行并标记
- dispatch_wait的作用就是,当原子性修改未完成的时候,等待token值改变后跳出循环
- 原子性操作,比较 + 交换。比较 &l->dgo_once 的值是否等于 DLOCK_ONCE_UNLOCKED,若是则将 (uintptr_t)_dispatch_lock_value_for_self() 赋值给 &l->dgo_once
https://xiaozhuanlan.com/topic/7916538240
线程逻辑
死锁问题:
dispatch_async(serial, ^{
sleep(1);
dispatch_sync(serial, ^{
NSLog(@"2-%@",[NSThread currentThread]);
});
NSLog(@"3-%@",[NSThread currentThread]);
});
- 假如都是同步,那就是都在主线程处理,但是我可以各自有队列,互相并无互相等待。A sync { B sync{} } AB在不同队列,那B做完再做A就是了
- 假如是同一个队列,那就需要不同线程, 而且还得是内层异步处理,因为外层等待 内层执行完成,而内层在外层队列后边
- dispatch_barrier_sync 同步的栅栏函数和同步没啥区别
- dispatch_barrier_async 异步的栅栏函数只有在并行自定义队列有用,毕竟串行异步不会开多线程,全球队列拦不住
死锁问题2
dispatch_sync(dispatch_get_main_queue(), ^{
NSLog(@"21-%@",[NSThread currentThread]);
});
- 在主队列里面跑主线程同步。。。 主队列不能同步操作,同步就卡,主队列一定在主线程执行,主线程不单单执行主队列
- 在主线程的同步操作,都请到别的队列
开线程问题
dispatch_queue_t queue = dispatch_queue_create("serial", DISPATCH_QUEUE_CONCURRENT);
for (int i = 0; i < 2000; i++) {
dispatch_sync(queue, ^{
sleep(0.01);
NSLog(@"%d - %@",i, [NSThread currentThread]);
});
}
- 同步的结果就是顺序打印
并行队列问题
NSLog(@"1");
dispatch_async(current, ^{
NSLog(@"2-%@",[NSThread currentThread]);
dispatch_sync(current, ^{
NSLog(@"3-%@",[NSThread currentThread]);
});
NSLog(@"4-%@",[NSThread currentThread]);
});
NSLog(@"5");
- 2、3、4在异步闭包中,并行与1、5 执行
- 3 同步住了这个异步闭包的线程,但是处于并行队列,队列会调度(同步所以不开线程,所以执行变成one by one),不会引起互相等待,所以2、3、4会顺序执行完成
- 串行队列必须等前面任务完成才会进行调度,线程有没有空都这样,所以如果同步在串行队列中,就会出现互相等待
- 并行队列会调度空闲线程执行任务,不会非要等前面的任务结束,如果是同步的并行,则因为不开新线程,所以执行就是当前线程 one by one,等有空的时候把我这个同步做了就完事
如果上面的 dispatch_sync 换成dispatch_barrier_sync 即使是并行也会导致异步线程自身的空等待,3、4都无法执行
// dispatch_group_async(group, current, ^{
// sleep(2);
// NSLog(@"2");
// });
//
// dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
// dispatch_group_notify(group, other, ^{
// NSLog(@"3");
// });
dispatch_group_notify(dispatch_group_t group,
dispatch_queue_t queue,
dispatch_block_t block);
dispatch_group_notify 中的队列参数代表持有block执行的队列,本身group管理的可以多个队列的任务
事件响应链
Thread 1 Queue : com.apple.main-thread (serial)
#0 0x00000001024a11fc in -[ViewController buttonAction] at
#1 0x000000010990b6c8 in -[UIApplication sendAction:to:from:forEvent:] ()
#2 0x00000001092c14bc in -[UIControl sendAction:to:forEvent:] ()
#3 0x00000001092c1800 in -[UIControl _sendActionsForEvents:withEvent:] ()
#4 0x00000001092be42c in -[UIButton _sendActionsForEvents:withEvent:] ()
#5 0x00000001092c04bc in -[UIControl touchesEnded:withEvent:] ()
#6 0x00000001024a0ca4 in -[WSButton touchesEnded:withEvent:] at
#7 0x0000000109940888 in -[UIWindow _sendTouchesForEvent:] ()
#8 0x0000000109941d30 in -[UIWindow sendEvent:] ()
#9 0x000000010991ffe0 in -[UIApplication sendEvent:] ()
#10 0x000000010999d96c in __dispatchPreprocessedEventFromEventQueue ()
#11 0x000000010999f5d0 in __processEventQueue ()
#12 0x00000001099984ac in __eventFetcherSourceCallback ()
#13 0x000000018037318c in __CFRUNLOOP_IS_CALLING_OUT_TO_A_SOURCE0_PERFORM_FUNCTION__ ()
#14 0x00000001803730d4 in __CFRunLoopDoSource0 ()
#15 0x0000000180372844 in __CFRunLoopDoSources0 ()
#16 0x000000018036ceb0 in __CFRunLoopRun ()
#17 0x000000018036c7a4 in CFRunLoopRunSpecific ()
#18 0x0000000188ff7c98 in GSEventRunModal ()
#19 0x000000010990637c in -[UIApplication _run] ()
#20 0x000000010990a374 in UIApplicationMain ()
#21 0x00000001024a1964 in main at
#22 0x0000000102661fa0 in start_sim ()
#23 0x0000000102735e50 in start ()
start_sim 是 模拟器的启动,如果真机,那就是dyld_start
- Application 接到响应
- GraphicsServices 的 GSEventRunModal
- CFRunLoopRunSpecific - CFRunLoopRun runloop跑起来
- __CFRunLoopDoSources0 事件处理
-__dispatchPreprocessedEventFromEventQueue 分发事件
- UIApplication 将事件分发到window
- UIResponer 响应者处理,touchesBegan - touchesEnd 这里如果处理了,不执行super,将不再往下传递
- sendAction totarget forEvent
- UIControl内部实际上是有一个可变数组(_targetActions)来保存Target-Action,数组中的每个元素是一个UIControlTargetAction对象。包含了 target action eventmask
- target持有control,control持有对象持有了target,没有循环引用事因为 UIControlTargetAction 持有的是weak的target
- sendAction就是根据这种机制,control作为响应者,把自己持有的target-action关系,交由UIApplication去触发 sendAction,最终由对应的target执行
- 也可以重写这里,交由其他target执行
- UIApplication sendAction
UIView的方法
-hitTest
-pointInside
UIResponder 的方法
-touchesBegan、touchesMoved、touchesEnded、touchesCancelled
-pressesBegan、pressesMoved、pressesEnded、pressesCancelled
-motionBegan、motionEnded、motionCancelled
-canPerformAction
-targetForAction
判断当前runloopmode
[NSProcessInfo processInfo].activeProcessorCount > 1 ? NSRunLoopCommonModes : NSDefaultRunLoopMode
动静态库区别
静态库
优点
- 本质是编译好的 .o文件集合,减少重复编译,工程编译速度加快
- 编译阶段链接到可执行文件,符号链接编译时确定,运行效率高
缺点
- 多个库都依赖相同静态库容易符号冲突
- 导致可执行文件变大
- 模块更新要重新编译发布
动态库
优点
- 共享使用,不导入mach-o 节约资源,减少可执行文件大小,减少内存空间
- 动态库不合如主可执行文件,不会出现符号冲突
缺点
- 链接耗时
- 整体ipa变大
动态库静态库编译的区别
- 静态库.a 里编译好的源文件的符号都会跟着工程里面的源文件符号一起存入mach-o
- 动态库 本身编译会打成自己的可执行文件 加上资源一起打成一个.framework,然后存放在ipa的Frameworks目录下
NotificationCenter 原理
https://cloud.tencent.com/developer/article/1645457
NotificationQueue 统一收归通知处理
网络请求
断点续传
在NSURLSession中,可以通过设置NSURLSessionConfiguration对象的HTTPAdditionalHeaders属性来添加Range字段
通过设置NSURLSessionDownloadTask对象的resumeData属性来保存已经下载的数据
URLConnection 文件下载是整个下载到内存,再写入沙盒
URLSession 是通过downloadTask载到沙盒的temp文件
控制方法也不一样,URLSession支持取消、暂停、继续。URLConnection只能取消
cookies
它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态
Cookie 使基于无状态的 HTTP 协议记录稳定的状态信息成为了可能。
NSURLProtocol的使用非常简单,但是可以做的事情却并不少。例如我们可以用其来做统一的网络处理,来做无侵入的网络监控等。
作为底层工具,统一的为Request添加通用Header字段。 统一的进行自定义用户认证。 做为环境切换工具,根据环境做URL的映射。 请求参数的整理和修改,统一增加通用参数。 统一修改或增加Response Header数据。 根据需求,做为本地的Mock工具,访问到本地服务或Mock远程数据。 监控端到端的网络请求性能,进行时间统计。
iOS是如何绘制渲染的
iOS 页面渲染 - UIView & CALayer https://mp.weixin.qq.com/s/ElGEsJoh3Y1-BWlvz1yJ9w
iOS 页面渲染 - 流程 https://mdnice.com/writing/cea532ead32a44b190b055fdbf2a3d65
https://juejin.cn/post/6846687595015962632 https://mdnice.com/writing/cea532ead32a44b190b055fdbf2a3d65
第一部分:屏幕显示
GPU渲染流程
1、顶点着色器 2、形状装配 3、几何着色 — 前面都是几何处理阶段,后面是光栅化阶段 4、光栅化 (转为像素点) 5、片段着色 (像素着色) 6、图层混合 blending
垂直同步信号VSync + 双缓冲机制
问题:
渲染好的位图存放在frameBuffer(前帧缓存)里面,如果切换的时候 新的还没绘制完,会导致展示一半,产生屏幕撕裂错觉
解决
1、苹果新增一个 backBuffer(后帧缓存),VSync切换的时候 是切换frameBuffer 到已经准备好的 backBuffer,所以当VSync切换的时候,缓冲池中的frame可以立马展示,解决屏幕撕裂问题
2、但是如果VSync切换的时候,backBuffer并没有渲染完成,就不会发生更换,产生卡住的表现(掉帧)
第二部分:绘制
问题:那么为什么 CALayer 可以呈现可视化内容
CALayer 是显示的基础:存储 bitmap。contents 属性指向一块缓存区,称为 backing store,可以存放位图(Bitmap) renderserver 将backing store 交给GPU渲染,将 backing store 中的 bitmap 数据显示在屏幕上
方式一:content image
直接放位图,比如把图片给layer展示 或者异步绘制好图片 再添加到layer (会有解码过程)
方式二:custom drawing
- setNeedDisplay
- [CALayer display] 进行是否代理执行判断【layer.delegate respondsTo @selector(displayLayer:)】
- NO -> 系统绘制流程
- YES -> 自定义绘制流程,可进行异步绘制操作
系统绘制
- create backing store(CGContextRef)
- 判断是否代理到UIView执行绘制【layer.delegate respondsTo @selector(drawInContext:)】
- NO -> layer drawInContext:
- YES -> UIView drawRect (交由UIView绘制)
- upload backing store to GPU (本身绘制是在CPU,最终结果会是一个 bitmap, 类型是 CGImageRef,写入 backing store, 通过 rendserver 交给 GPU 去渲染,将 backing store 中的 bitmap 数据显示在屏幕上) CABackingStoreUpdate_
异步绘制
- UIKit都是在主线程操作UI,UI一多,性能瓶颈就较明显
- (UIKit非线程安全)为何这样设计
- YYAsyncLayer
//重写display 在display的时候执行异步绘制逻辑
- (void)display {
super.contents = super.contents;
[self _displayAsync:_displaysAsynchronously];
}
//回到主线程赋值contents bitmap
- (void)_displayAsync:(BOOL)async {
__strong id<YYAsyncLayerDelegate> delegate = (id)self.delegate;
YYAsyncLayerDisplayTask *task = [delegate newAsyncDisplayTask];
dispatch_async(YYAsyncLayerGetDisplayQueue(), ^{
//// XXXXXX 绘制操作(CoreGraphics是线程安全的 )XXXXXX
dispatch_async(dispatch_get_main_queue(), ^{
//绘制产物赋值给content,必须要回到主线程
self.contents = (__bridge id)(image.CGImage);
});
});
//事务的统一提交,模仿CA的Runloop监听,可以自定义提交事务,会根据runloop状态统一处理
[[YYTransaction transactionWithTarget:self selector:@selector(contentsNeedUpdated)] commit];
//重写 setNeedsDisplay 事务提交后还是通过系统的display标记,推动UI绘制渲染流程
- (void)setNeedsDisplay {
[self _cancelAsyncDisplay];
[super setNeedsDisplay];
}
问题:为什么有UIView 还有CALayer,在绘制上,他们有什么差异
结论:
CALayer:继承自 NSObject, 负责图像渲染,属于 QuartzCore 框架 (跨平台) UIView:继承自 UIResponder, 主要负责事件响应,属于基于 UIKit 框架
UIView处理事务、CALayer处理画布展示,UIView的所有的布局、UI样式都是基于CALayer的底层封装而来(CALayerDelegate)
验证
1、UIView的drawRect 本质上是 CAlayer的 drawInContext
2023-10-02 11:19:35.305335+0800 iOSDemo2[69048:9796783] -[MYButton drawRect:]
2023-10-02 11:19:35.305466+0800 iOSDemo2[69048:9796783] layer - -[MYButtonLayer drawInContext:]
2、UIView 使用的所谓 frame 、bounds 、center 等属性,其实都是从 CALayer 中返回的,而 frame 只是 CALayer 中的一个计算型属性而已
3、CALayer有hitTest 可以判断是否有事件落在当前layer
问题:Core Animation 流水线的工作流程
- Application(Core Animation)
- 事件 / 布局变化 / 绘制 / 解码等 -> Commit Transaction 提交事务到RenderServer (CPU计算,下一次runloop休眠前提交渲染)
- 细分如下:
- Layout(构建视图)
- Display(绘制视图)
- Prepare(图片解码等额外操作)
- Commit(图层打包发送到RenderServer)
- Render Server(Core Animation)渲染服务,独立进程
- Decode (解码收到的提交上来的图层内容 -> 呈现树)
- Draw calls (执行OpnenGL、Metal,并调用GPU)
- GPU
- Render 图像渲染
- Display
- 根据垂直信号展示
问题:Commit打包的图层是什么,Layer 内部的三份 layer tree 是什么
CoreAnimation作为一个复合引擎,将不同的视图层组合在屏幕中,并且存储在图层树中,向我们展示了所有屏幕上的一切。
整个过程其实经历了三个树状结构,才显示到了屏幕上:模型树–>呈现树–>渲染树
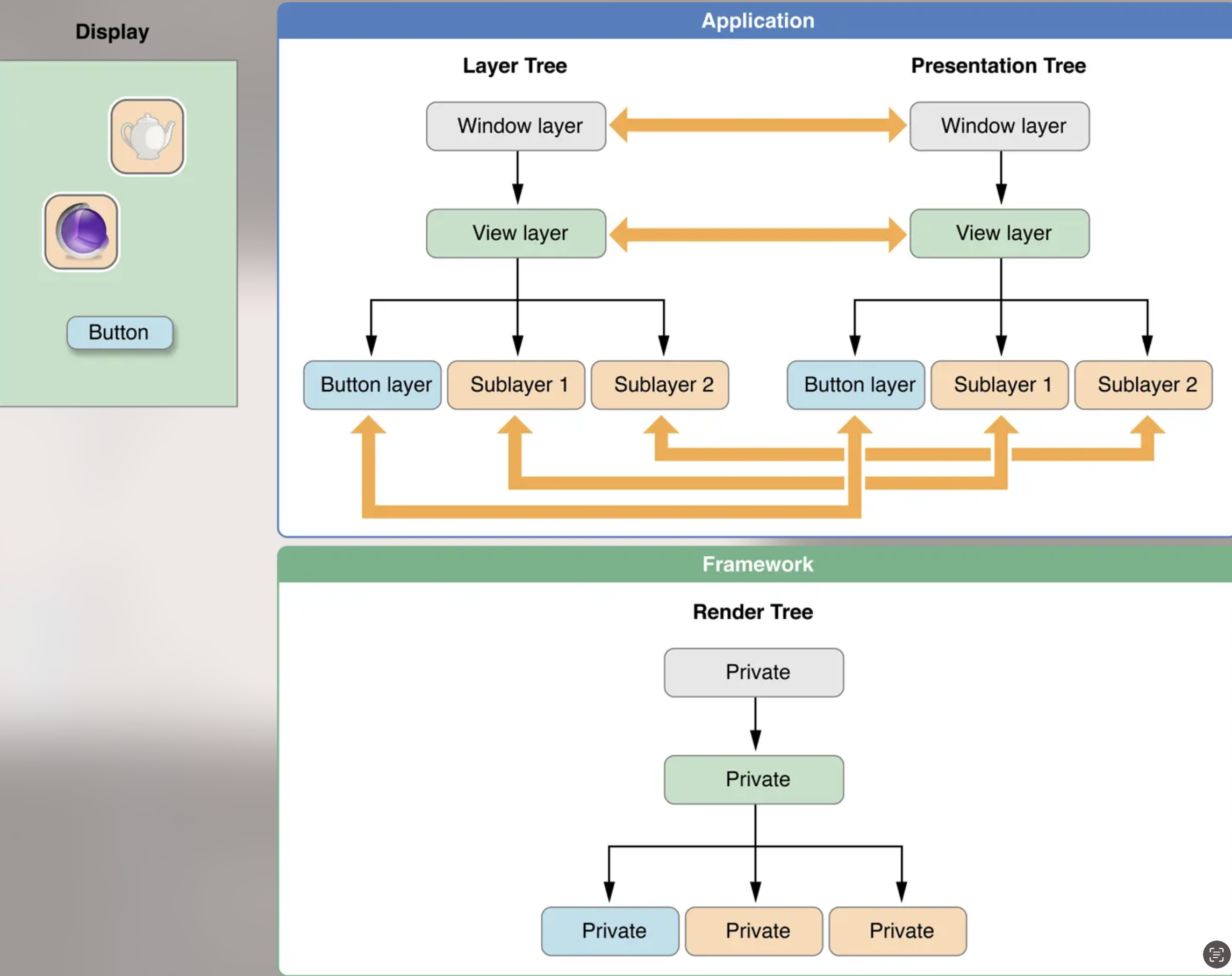
- layer tree(model tree):一般我们称模型树, 也就是各个树的节点的 model 信息, 比如常见的 frame, affineTransform, backgroundColor 等等, 这些 model 数据都是在开发中可以设置的, 我们任何对于 view/layer 的修改都能反应在 model tree 中
- presentation tree:这是一个中间层,我们 APP 无法主动操作, 这个层内容是 iOS 系统在 Render Server 中生成的
- render tree:这是直接对应于提交到 render server 上进行显示的树
1、我们操作的是模型树,在重绘周期最后,我们会将模型树相关内容(层次结构、图层属性和动画)序列化,通过IPC传递给专门负责屏幕渲染的渲染进程RenderServer
2、渲染进程拿到数据并反序列化出树状结构–呈现树,这个呈现图层实际上是模型图层的复制,但是它的属性值代表了在任何指定时刻当前外观效果 (我们可以通过CALayer的presentationLayer方法来访问对应的呈现树图层)
3、CoreAnimation动画,即基于事务的动画,是最常见的动画实现方式。动画执行者是专门负责渲染的渲染进程,操作的是呈现树 presentationLayer (如果需要处理Layer动画中的事件处理,可以通过hitTest 的 presentationLayer的位置来确定,比如是否点中动画中的图层)
问题:如果我们变更了UI 如何立马主动通知重新绘制渲染,如果不主动通知,什么时候会重新绘制渲染
结论:变化UI属性会自动给当前UI脏标记 setNeedsLayout ,如果需要额外刷新的UI 可以手动标记 setNeedsLayout ,下一轮循环会处理然后休眠时递交渲染
1、setNeedsLayout: 脏标记,不会马上调用layoutsubviews、子View的标记,下一轮runloop再处理
2、layoutIfNeeded: 立即执行layoutsubviews、子View的标记,前提是执行的UI 已被提前脏标记
验证
较好的验证就是当约束赋值之后,setNeedsLayout并不会改变frame,但是 layoutIfNeeded 会。
UIControl 点击触发 UIControl 的高度约束变化(不用按钮的原因:按钮有高亮状态、也会触发UI刷新,影响判断) 下面分别用setNeedsLayout、layoutIfNeeded操作验证高度约束的变化
setNeedsLayout 打标记
高度在setNeedsLayout方法前后没有发生变化
2023-10-02 11:16:11.962687+0800 iOSDemo2[67801:9787531] begin-30.000000
2023-10-02 11:16:11.962859+0800 iOSDemo2[67801:9787531] content - -[MYContentView setNeedsLayout]
2023-10-02 11:16:11.963062+0800 iOSDemo2[67801:9787531] end-30.000000
//下一轮循环进入休眠前才处理
2023-10-02 11:16:11.963536+0800 iOSDemo2[67801:9787531] runLoopObserverCallBack-kCFRunLoopBeforeTimers-2
2023-10-02 11:16:11.963803+0800 iOSDemo2[67801:9787531] runLoopObserverCallBack-kCFRunLoopBeforeSources-4
2023-10-02 11:16:11.964036+0800 iOSDemo2[67801:9787531] runLoopObserverCallBack-kCFRunLoopBeforeWaiting-32
2023-10-02 11:16:11.964230+0800 iOSDemo2[67801:9787531] content - -[MYContentView setNeedsLayout]
2023-10-02 11:16:22.695517+0800 iOSDemo2[67801:9787531] layer - -[MYButtonLayer setNeedsLayout]
2023-10-02 11:16:22.695700+0800 iOSDemo2[67801:9787531] content - -[MYContentView layoutSubviews]
2023-10-02 11:16:22.695828+0800 iOSDemo2[67801:9787531] -[MYButton layoutSubviews]
layoutIfNeeded 立刻执行
2023-10-02 11:17:50.074031+0800 iOSDemo2[68421:9791495] begin-30.000000
2023-10-02 11:17:50.074156+0800 iOSDemo2[68421:9791495] content - -[MYContentView setNeedsLayout]
2023-10-02 11:17:54.508969+0800 iOSDemo2[68421:9791495] layer - -[MYButtonLayer setNeedsLayout]
2023-10-02 11:17:54.509150+0800 iOSDemo2[68421:9791495] content - -[MYContentView layoutSubviews]
2023-10-02 11:17:54.509246+0800 iOSDemo2[68421:9791495] -[MYButton layoutSubviews]
2023-10-02 11:17:54.509371+0800 iOSDemo2[68421:9791495] content - -[MYContentView layoutIfNeeded]
2023-10-02 11:17:54.509477+0800 iOSDemo2[68421:9791495] end-60.000000
//下一轮循环进入休眠
2023-10-02 11:17:54.509751+0800 iOSDemo2[68421:9791495] runLoopObserverCallBack-kCFRunLoopBeforeTimers-2
2023-10-02 11:17:54.509864+0800 iOSDemo2[68421:9791495] runLoopObserverCallBack-kCFRunLoopBeforeSources-4
2023-10-02 11:17:54.509989+0800 iOSDemo2[68421:9791495] runLoopObserverCallBack-kCFRunLoopBeforeWaiting-32
注意:在用UIButton触发事件的时候,发现end后、runloop前还有一部分代码
2023-10-02 10:48:08.814999+0800 iOSDemo2[57890:9735779] end-60.000000
//这些又是啥,原来是UIButton的高亮色导致,点击按钮触发了按钮的高亮色刷新,换成UIControl就不会有这部分
2023-10-02 10:48:08.815352+0800 iOSDemo2[57890:9735779] layer - -[MYButtonLayer setNeedsLayout]
2023-10-02 10:48:08.815534+0800 iOSDemo2[57890:9735779] layer - -[MYButtonLayer setNeedsLayout]
2023-10-02 10:48:08.815734+0800 iOSDemo2[57890:9735779] -[MYButton setNeedsLayout]
//下一轮runloop
2023-10-02 10:48:08.816112+0800 iOSDemo2[57890:9735779] runLoopObserverCallBack-kCFRunLoopBeforeTimers-2
注意:如果我们变更了背景色alpha等,以上结论还有效么
结论: 1、如果是如背景色、alpha等的改变,调用的就是drawRect、drawInContext 2、layoutIfNeeded 只是提前处理layoutsubviews布局,并不影响 drawRect
2023-10-02 11:19:35.303373+0800 iOSDemo2[69048:9796783] begin-30.000000
2023-10-02 11:19:35.303613+0800 iOSDemo2[69048:9796783] content - -[MYContentView setNeedsLayout]
2023-10-02 11:19:35.303852+0800 iOSDemo2[69048:9796783] layer - -[MYButtonLayer setNeedsLayout]
2023-10-02 11:19:35.303983+0800 iOSDemo2[69048:9796783] content - -[MYContentView layoutSubviews]
2023-10-02 11:19:35.304134+0800 iOSDemo2[69048:9796783] -[MYButton layoutSubviews]
2023-10-02 11:19:35.304247+0800 iOSDemo2[69048:9796783] content - -[MYContentView layoutIfNeeded]
2023-10-02 11:19:35.304437+0800 iOSDemo2[69048:9796783] end-60.000000
2023-10-02 11:19:35.304703+0800 iOSDemo2[69048:9796783] runLoopObserverCallBack-kCFRunLoopBeforeTimers-2
2023-10-02 11:19:35.304794+0800 iOSDemo2[69048:9796783] runLoopObserverCallBack-kCFRunLoopBeforeSources-4
2023-10-02 11:19:35.304937+0800 iOSDemo2[69048:9796783] runLoopObserverCallBack-kCFRunLoopBeforeWaiting-32
///为什么调用了 layoutIfNeeded 还是在下一轮循环处理
2023-10-02 11:19:35.305122+0800 iOSDemo2[69048:9796783] content - -[MYContentView drawRect:]
2023-10-02 11:19:35.305335+0800 iOSDemo2[69048:9796783] -[MYButton drawRect:]
2023-10-02 11:19:35.305466+0800 iOSDemo2[69048:9796783] layer - -[MYButtonLayer drawInContext:]
注意:并不推荐直接调用Layoutsubviews、drawRect,容易产生很多不确定性问题
Layoutsubviews 通过 setLayout标记
drawRect 通过 setNeedDisplay、setNeedsDisplayInRect:标记
1、系统中 Layoutsubviews 会调用的场景
- addSubviews
- 改变frame
- 如果是scrollView,滑动也会触发
- 旋转屏幕触发横竖屏样式切换
- 自己的frame变化的时候,父类的layoutsubviews也会调用
- 主动调用 Layoutsubviews(不建议)
- setNeedsLayout layoutifNeed 前提是已标记 (frame变化一半都会自动标记)
- init 并不会调用 Layoutsubviews
2、系统中 drawRect 会调用的场景
- setNeedDisplay (更改背景色、alpha 都会自动标记,或者可以手动调用)(rect不能为0)
- loadView ->ViewDidload ->drawRect: 初始化的时候调用
- sizeThatFits
iOS 堆栈符号解析
https://juejin.cn/post/6844903598011187213
原理: dSYM 文件是指具有调试信息的目标文件,dSYM 中存储着文件名、方法名、行号等信息,是和可执行文件的 16 进制函数地址一一对应的,通过分析崩溃的崩溃文件可以准确知道具体的崩溃信息
1、由于ASLR的原因,运行内存地址和mach-o的内存地址并不相同,中间有偏移量 2、偏移量 = 运行时堆栈地址 - 应用堆栈在操作系统堆栈中的起点 3、根据dsym获取mach-o起始地址 4、就可以得到运行内存地址 在 dsym中对应的内存地址 = dsym起始地址 + 偏移量
缓存淘汰算法
FIFO LRU(最近最少使用,最近一段时间最少被访问的数据淘汰掉) LFU(最不经常使用、基于最近访问频率来进行淘汰) 都适用于什么情况
LRU 这个缓存算法将最近使用的条目存放到靠近缓存顶部的位置。当一个新条目被访问时,LRU将它放置到缓存的顶部。当缓存达到极限时,较早之前访问的条目将从缓存底部开始被移除。这里会使用到昂贵的算法,而且它需要记录“年龄位”来精确显示条目是何时被访问的。此外,当一个LRU缓存算法删除某个条目后,“年龄位”将随其他条目发生改变。
LFU 最不经常使用、基于最近访问频率来进行淘汰
fishHook原理
问题:fishhook无法hook自定义函数,只能hook动态链接库函数
自定义函数在代码段,代码段具有只读可执行权限,因此fishhook无法hook自定义函数
fishhook能够hook 动态链接库Foundation.framework中的NSLog,重要原因之一就是:函数符号位于数据段,只有数据段内容才能被修改
动态库链接进来需要rebase、rebind,符号地址是需要修改的,所以存放在数据段__DATA__
1、fishhook的原理就是符号替换,所以__Data__数据段的符号才能hook
2、符号的内存地址需要处理地址偏移问题,所以fishhook根据内存地址偏移,加上新老符号信息,完成hook操作
IPC
https://segmentfault.com/a/1190000002400329
PCM
量化 / 比特率 / 码率 :每秒的数据量。这里形容 一段采样的存储数据量(bit) = 采样率 * 声道数 * 位深
PCM无损无压缩 按 48000 * 2 * 16 = 1536kbps, 换算到网络传输,每秒传输1536k bit的数据,一分钟相当于 1536k * 60 / 8 / 1024 / 1024 = 10.1M 的流量,成本较高
- 音频压缩
RTC场景下,往往还需要再使用 AAC、OPUS 等编码算法做编码压缩,进一步减小带宽、存储的压力
- 采样率 (采样率越大,还原度越高,占用内存越多)
-
每秒采集的点位数量 常用 441000Hz 480000Hz
-
8KHz在语聊、通话场景,满足基本的沟通目的,同时有效减少数据量、兼容各种传输/存储环境。人说话声音频率一般在300-700Hz之间,最大区间一般为60Hz-2000Hz
-
16KHz、32KHz 在保证基本沟通的基础上,进一步提升音质,同时平衡带宽、存储的压力。某些音频处理算法会要求使用32KHz的采样率
-
44.1KHz,48KHz 在比如在线KTV、音乐教学等场景,对音质要求比较高,可考虑进一步提升采样率,根据奈奎斯特采样定理,理论上采样率大于40KHz则完全足够
-
- 声道数(一般来说声道数越多,声音的方向感、空间感越丰富,听感也就越好)
- 客户端一般默认双声道数据,手机设备一般都配备
- 多个音频源采集到的声音,然后在多个扬声器播放,自然越多越丰富
- 位深 (深度越大,采集的内容越丰富)
- 一个bit大概6分贝声音,16bit是常用的采样位深,一般记录92分贝动态范围音频(100分贝人类就会失去听觉,所以够用了)
视频的本质 - 图像 (一帧帧连续展示的图像)
iOS视频采集的时候支持输出三种数据格式 420v 420f和BGRA。 BGRA没什么好说的就是RGB三色加上alpha通道,420f和420v都是YUV格式的,区别在于color space。f 指 Full Range,v 指 Video Range
Full Range的 Y 分量取值范围是 [0,255] Video Range的Y分量取值范围是 [16,235]
颜色有两个属性color range和color space
color range 分为 FullRange和VideoRange
color space 主要是BT.601-4和BT.709-2 (RGB <-> YUV 转换标准,后者是新的,前者是老的标准)
从采集编码到解码渲染,整个过程中,颜色空间的设置都必须保持一致,如果采集用了Full Range而播放端用Video Range,那么就会看到曝光过度的效果了
- 色彩空间(color space)
在 RTC 应用中,主要使用的是 RGB 和 YUV
- RGB 在 RGB 模型下,图像的每一个像素点都会存储 R、G、B 三个分量,每个分量取不同的数值( 0 ~ 255 )
问题: 每个像素点必须同时存储 R、G、B 三个分量值才能正确表示颜色,这导致它不便于做编码压缩,如果用于存储或传输,会占用大量的空间和带宽
- YUV
- YUV 色彩空间也有三个分量 Y、U、V,但和 RGB 不同的是,其三个分量并非都参与颜色的表示
- Y 分量用于表示明亮度(Luminance),决定一个像素是明、或暗(可以理解为是黑、或白)
- 而 U、V 分量表示色度(Chrominance)、浓度(Chroma),用于定义色彩和饱和度
- 人眼对Y感知明显,对U、V没有那么明显,可以压缩
- 色彩空间转换
- 视频采集设备一般输出的是 RGB 数据,我们需要将其转换为 YUV 数据再进行后续的处理、编码和传输;
- 同样的,显示设备通过传输、解码环节获取到 YUV 数据后,也需要将其转换为 RGB 数据,再进行消费展示
- RGB的采样和存储
- RGB 三个分量,每个分量的采样数是一样的,一样的重要程度 (所以不适合压缩)
- RGB 三个分量采样后,在内存中是依次排列存储的,但是实际存储可能因为应用场景不一样规则不一样:MATLAB 使用的存储顺序为 R、G、B,而 OpenCV 则使用 B、G、R
- 如果读取的时候错误顺序读取,展示的效果就偏色了
- RGBA 最后的A就是alpha通道,表示透明度
- 每一个分量( 0 ~ 255 ),占8位,所以一张RGB图内存 = 8 * 3 widthheight bit。RGBA 就 * 4
- YUV的采样和存储
采样方式
YUV 4:4:4 (每1个Y 都有对应的UV) 3bit
这种方式也就是上文所说的,YUV分量全部进行采样
YUV 4:2:2 (每2个Y 共用一个UV) 1 bit + 0.5bit + 0.5 bit
在所有像素上,Y分量全部采样。 在同行的像素上, U 和 V 分量分别 交替 进行采样;
YUV 4:2:0【重点】 (每4个Y 共用一个UV) 1bit + 0.25bit + 0.25bit
在所有像素上,Y分量全部采样。 在(偶数行), U 分量 间隔 进行采样,而不采样V分量。 在(奇数行), V 分量 间隔 进行采样,而不采样U分量。
以上面的8个像素为例,那么我们采集到的数组长度则分别为:
YUV 4:4:4 8 + 8 + 8 长度为24 YUV 4:2:2 8 + 4 + 4 长度为16,是第一种的 三分之二 YUV 4:2:0 8 + 2 + 2 长度为12,是第一种的 二分之一 所以使用420的采样方式,所需的存储空间会大大减小。
CVPixelBufferRef 像素缓冲区类型 pixelFormat : 32BGRA
CGColorSpaceRef
- 10.2 向 SDK 投送自己采集的视频帧 *
- 使用此接口可以向 SDK 投送自己采集的视频帧,SDK 会将视频帧进行编码并通过自身的网络模块传输出去。
- 参数 {@link TRTCVideoFrame} 推荐下列填写方式(其他字段不需要填写):
-
- pixelFormat:推荐选择 {@link TRTCVideoPixelFormat_NV12}。
-
- bufferType:推荐选择 {@link TRTCVideoBufferType_PixelBuffer}。
-
- pixelBuffer:iOS/Mac OS 平台上常用的视频数据格式。
-
- data:视频裸数据格式,bufferType 为 NSData 时使用。
-
- timestamp:时间戳,单位为毫秒(ms),请使用视频帧在采集时被记录下来的时间戳(可以在采集到一帧视频帧之后,通过调用 {@link generateCustomPTS} 获取时间戳)。
-
- width:视频图像长度,bufferType 为 NSData 时填写。
-
- height:视频图像宽度,bufferType 为 NSData 时填写。
-video_size:分辨率 -pixel_format:像素格式 默认是yuv420p -framerate:帧率(每秒采集多少帧画面) 默认是ntsc,也就是30000/1001,约等于29.970030 -list_devices:true表示列出avfoundation支持的所有设备
ld64
https://www.jianshu.com/p/f141a368abb5 https://www.zhihu.com/pin/1661784546335944704?utm_id=0 https://medium.com/tokopedia-engineering/a-curious-case-of-mach-o-executable-26d5ecadd995 https://www.jianshu.com/p/47d03a2dea02
https://mp.weixin.qq.com/s?__biz=MzI1MzYzMjE0MQ==&mid=2247486932&idx=1&sn=eb4d294e00375d506b93a00b535c6b05&chksm=e9d0c636dea74f20ec800af333d1ee94969b74a92f3f9a5a66a479380d1d9a4dbb8ffd4574ca&scene=21#wechat_redirect
https://juejin.cn/post/6936377886555242509
https://juejin.cn/post/6896728016953540621
https://juejin.cn/post/6953478561579663397
https://www.jianshu.com/p/50e88f9fbfa8
https://huang-libo.github.io/posts/App-Startup-Time-dyld/#dyld-2-的执行流程
weak、sidetable https://blog.csdn.net/m0_52192682/article/details/125948436?ydreferer=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbS5oay8%3D
taggedpoint https://blog.devtang.com/2014/05/30/understand-tagged-pointer/
block
https://luochenxun.com/ios-mt-block3/
runloop
https://cloud.tencent.com/developer/article/1630860
多线程 https://juejin.cn/post/7062986669275742244
hook load
https://blog.csdn.net/littleFish_ZYY/article/details/119786321
事件传递 https://blog.csdn.net/u011774517/article/details/66472746
内存映射 mmap https://juejin.cn/post/6844904154826031118
图片速度加载优化 http://blog.cnbang.net/tech/2578/
readimage https://juejin.cn/post/6987311066778697736
MJ 音视频 https://www.cnblogs.com/mjios/category/1938094.html